Inhaltsverzeichnis
The idea: automatic depositing the project’s TEI files at Zenodo
[Update 2023-01-25: There is a recording of an e-editiones workshop. However, the TEI2Zenodo platform mentioned in the article and in the workshop is unfortunately no longer reliably available.]
We have been using the github-zenodo integration for a while already with our source code releases. This allows us to deposit our code, update the deposit with new releases and get a persistent identifier for each of the versions. Since we are facing similar requirements for our TEI XML files, I have investigated how we could take profit of this or a similar mechanism. The crucial difference is this: The integration as it is makes deposits from releases/snapshots of the whole github repository, i.e. of all the files that are in the version control system. This is good for software, where all the files depend on each other and make sense only in the context of an encompassing application. But for our TEI sources, it would be better to have deposits for individual files (and persistent identifiers for them) rather than for the collection as a whole.
So I have developed a „TEI2Zenodo“ service (in the following just „t2z“) that can take care of uploading our files to zenodo. The idea is that a project or an institution that regularly wants to commit TEI XML files to long-term archival can host an instance of it and do its uploads via this instance. I have used it to upload 16 of our source TEI files automatically from our github repository.
Besides a „manual mode“ (more on which later), it can be triggered to retrieve individual TEI XML files from a github repository, parse them for the metadata that zenodo requires, and upload them. In the process zenodo assigns a DOI and since such an identifier is a bit of information that you would normally like to record inside your TEI file, I have enabled to service to modify the TEI file before uploading, putting the new DOI in there. In order not to have divergent copies of the file between the zenodo and github repository, it then commits the modified file (with its DOI) also back to github.
Note that Zenodo requires some metadata fields to be present and to use a controlled vocabulary. Since this webservice cannot perform more than very simple XPath operations for extracting such values, it cannot create the required terms and instead presupposes that the submitted TEI files already make use of this controlled vocabulary, a presupposition that goes beyond what the TEI guidelines recommend. Therefore, I am using a prepare step that makes the TEI files fit for this procedure. (It resolves XIncludes, puts zenodo’s contributor role names into the editor role attributes, and adds an n="cc-by" attribute to the licence element.) Everything necessary for this is published in our TEI files repository at github.
Inspired by an exchange on the TEI Mailing list, and providing both more security and more flexibility, I have made all of the above optional and added many more options and switches. (To be honest, it has reached a state where I am no longer certain that I have tested everything.) To learn more about the modes of operation, configuration options etc. see the software’s Readme file.
Anyway, here’s how it plays out for us:
Usage in the Salamanca project
I have deployed the service on one of our virtual machines and given it a configuration that includes my zenodo and my github personal access tokens, our TEI files repository at github along with some more information for controlling the t2z process. Over at github, I have configured a webhook to send notifications upon push events to the virtual machine where t2z is listening. We have two branches in our github repository: master and publish, and I have configured t2z to react only to events related to the publish branch. (This results in some steps being more difficulty than necessary for the sake of opportunities to intervene. Maybe you want to configure just the master branch…)
So, when I am committing one of our TEI files to the master branch, as expected, nothing happens. (But I have made sure to include my trigger phrase „zenodo“ in the commit message and also the word „test“ in order to be given a chance to look at the deposit before it will be published.)

Now my publish branch is one commit behind master. Let’s see what will happen if I git checkout publish; git merge master; git push: Magic!
What happened at zenodo
First of all, if we have a look at our Zenodo „Uploads“ page, there is the new deposit waiting to be reviewed and published:

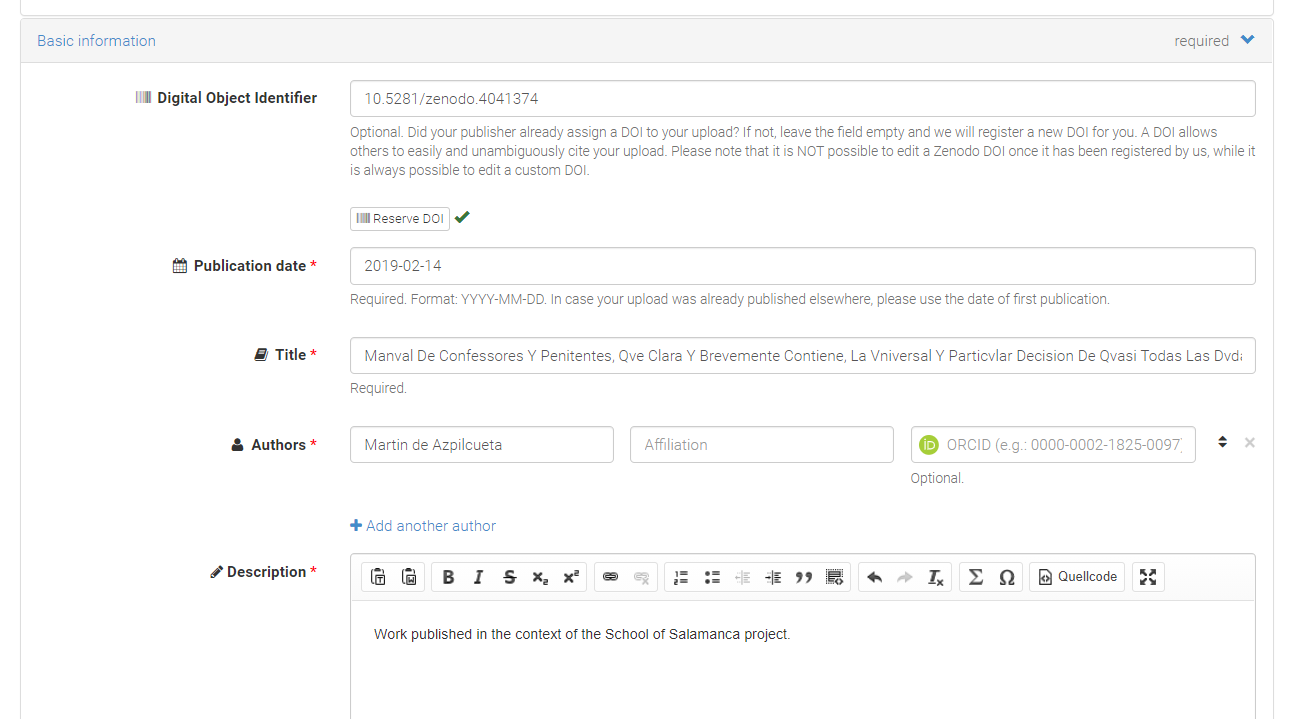
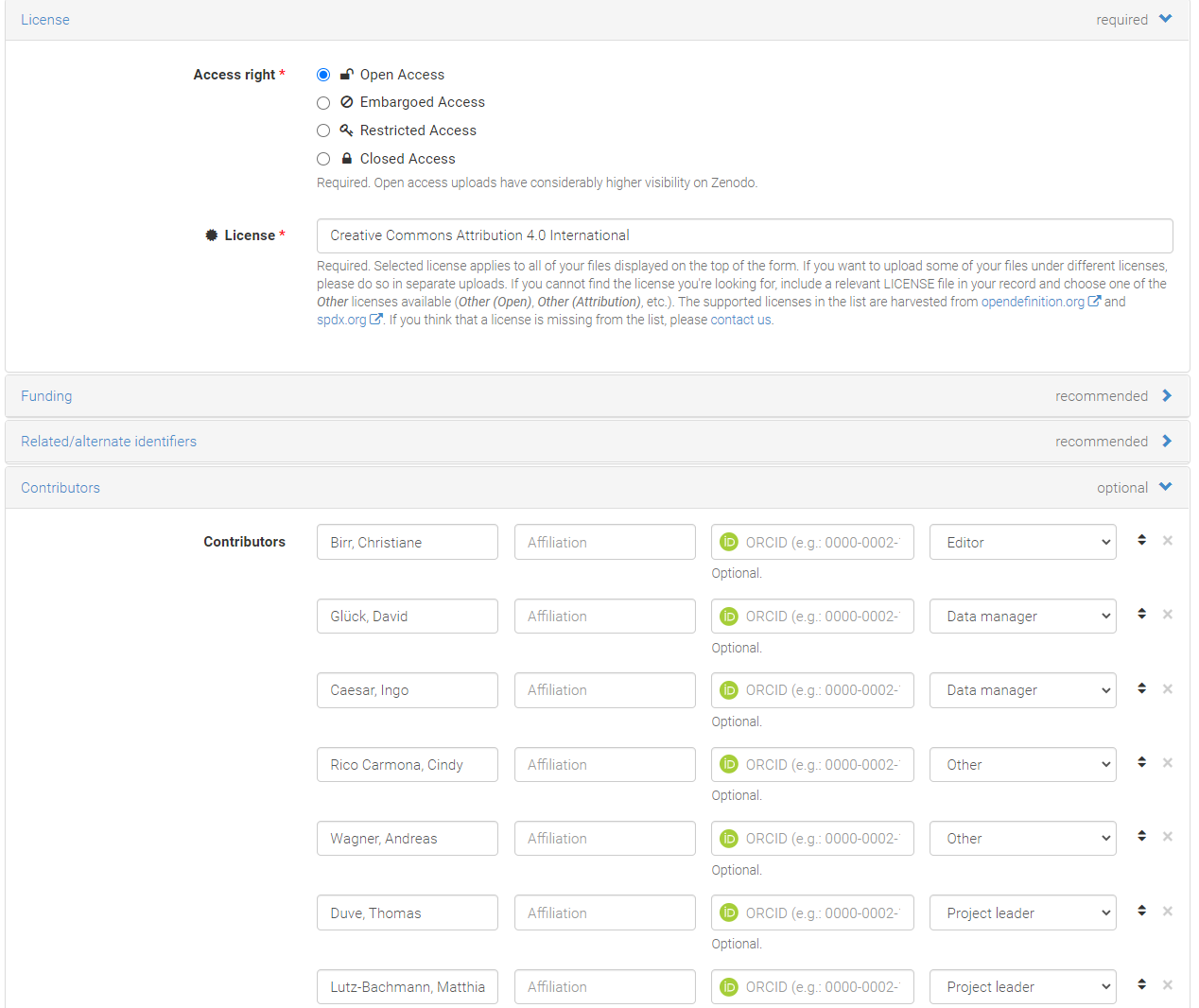
If we have a look inside, we can see that the Document’s title, author, the original date of its digital publication on our project’s website have been correctly extracted, and we have a nice and shiny new zenodo DOI. Plus we have licence information and contributor information…
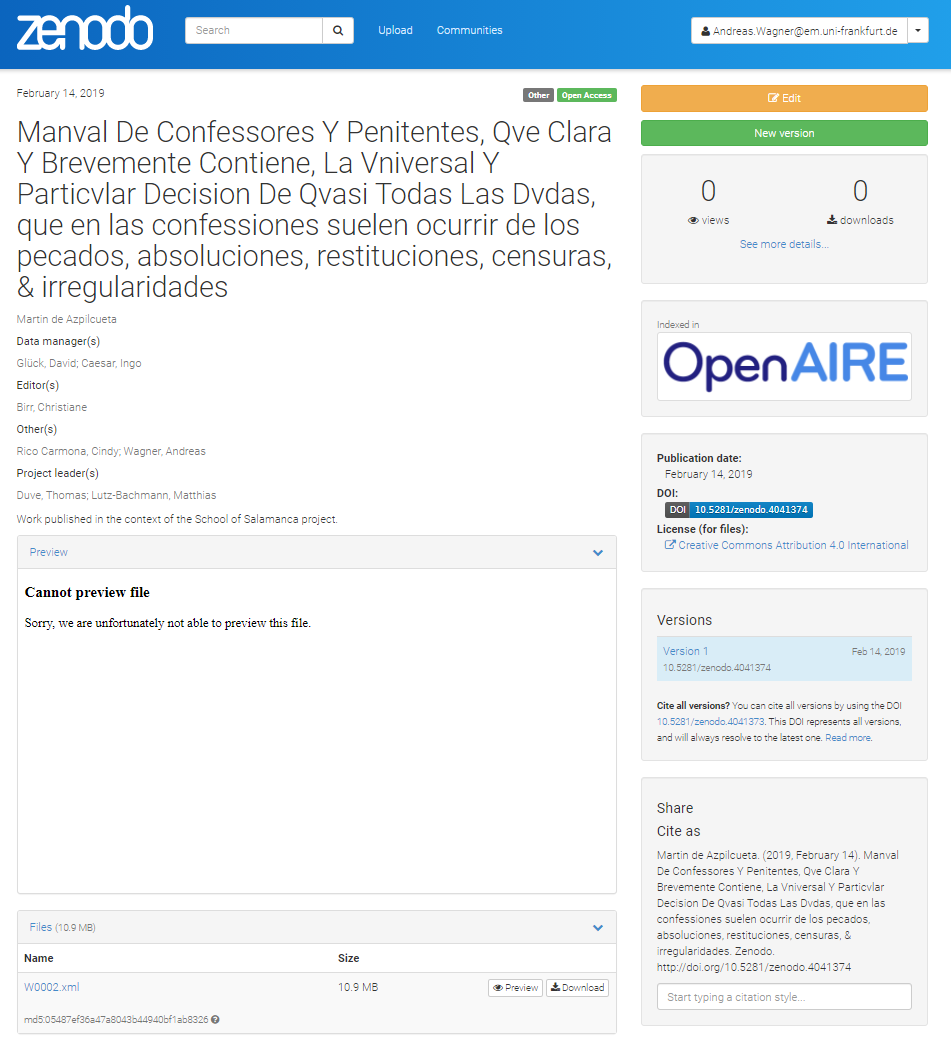
So, everything seems fine and I proceed to „publish“ the deposit at zenodo:
And what has happened over at github?
What happened at github
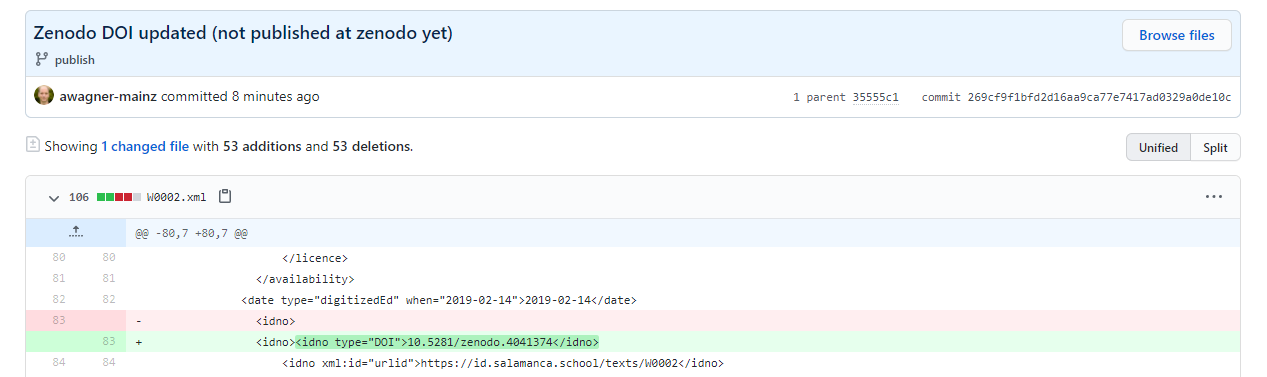
Having a look at the commit history of the publish branch, we see that there is our original „Publish … at zenodo (test).“ commit. But then, there is a new one, saying „Zenodo DOI updated (not published at zenodo yet).“ Well, since I have just did publish the deposit, this may seem a bit misleading, but at the time the commit was created, it had not been not published yet.

And having a look at that latest commit, we can see that it has added the DOI and also added a „Added DOI XY/Z123 (automatically added by tei2zenodo service).“ entry in the RevisionDesc section.

What happened on our server
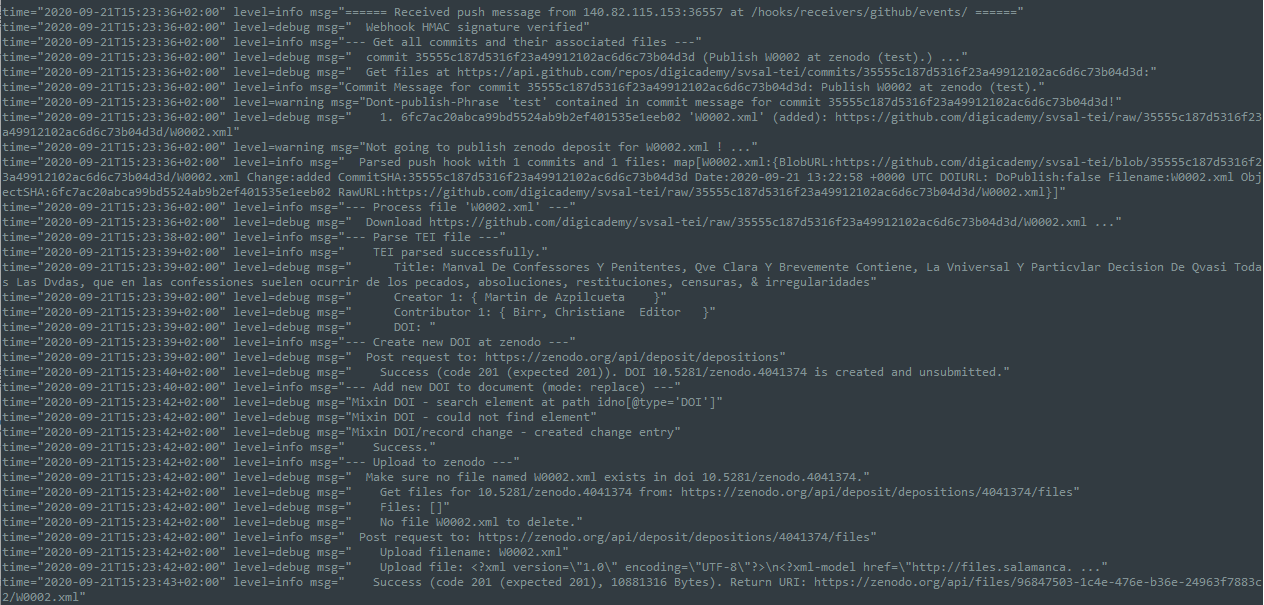
For completeness‘ sake, here are the logs that the service has produced for this process. (Here, you can also see that the new commit adding the DOI to the file on github has of course triggered another webhook, which the service then recognised and ignored as one it was itself responsible for.)
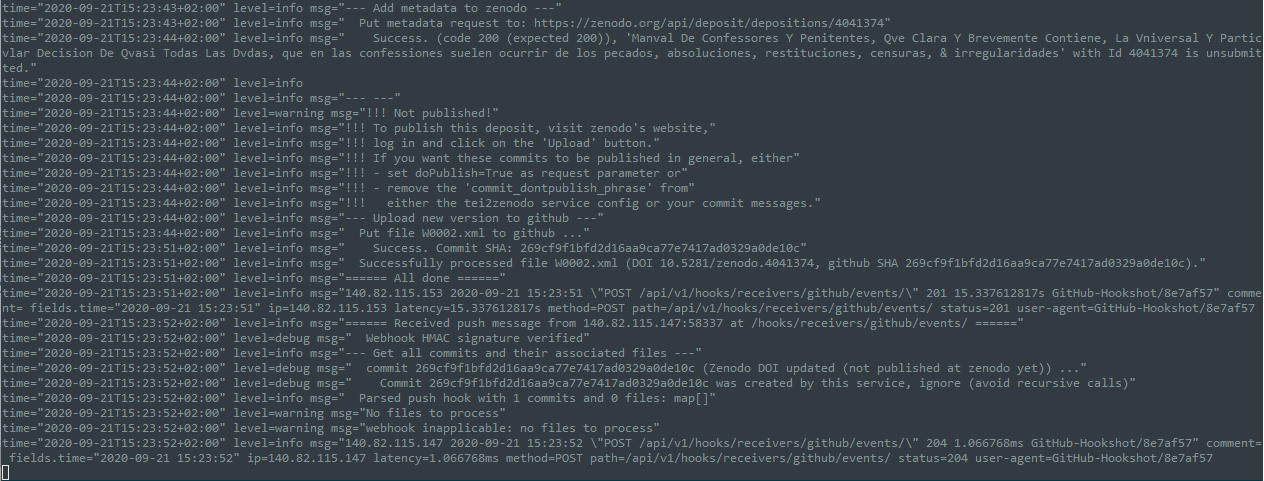
Multi-file commits, updates and caveats
Multi-file actions
Since this went well, I want ahead and committed three files at once, publishing them immediately (by not mentioning „test“ in the commit message). And it worked correctly, too: It retrieved the three files W0003.xml, W0004.xml and W0007.xml and processed them one after the other. (The push event that the service got notified above might contain several commits, each of which may have affected several files. So the service retrieves the most current version of all files that have been affected (except for deletions and renamings) by relevant commits (i.e. containing the trigger phrase) and processes them.)
Updates
Since now the files contain DOI ids, when I commit a mere update to one of the files, the service is going to find the file mentioned in the DOI key and upload the updated file as a new version of the former deposit. I have configured our instance so that the DOI in the updated file gets replaced by the one for the update deposit, but I could also have it just add an addditional DOI element every time such an update occurs.
Caveats
Beware, tho, that when the processing of one of the files fails, the batch processing is aborted and the remaining files are in your github repository but not on zenodo. (And it may require committing a change to them to reinitiate the process when the problem is fixed.) The payload/response information of the failed webhook in github’s webhook overview may provide an indication of why the process has failed, in addition to the log of the service itself. Presently, the only way to do this is monitor the log, or github’s webhook page, or make sure everything is where it’s supposed to be both in zenodo and github. In the future, I may add a failure notification option (e.g. by mail).
In practice, I had many runs in which the editors had not been marked up as originally expected (e.g. multiple roles, or no role at all), which resulted in many procedures of removing the files from the git repo, committing/pushing changes, fixing things and adding files again and committing/pushing again – all across several branches. Better pay attention that your TEI files are conformant in the first place. Unfortunately, at the moment, there is no validation step in the beginning, but I will try and add one of sorts.
Also, remember to pull (and eventually merge) the changes that are now at github’s copy of the TEI files (the publish branch, in our case)!
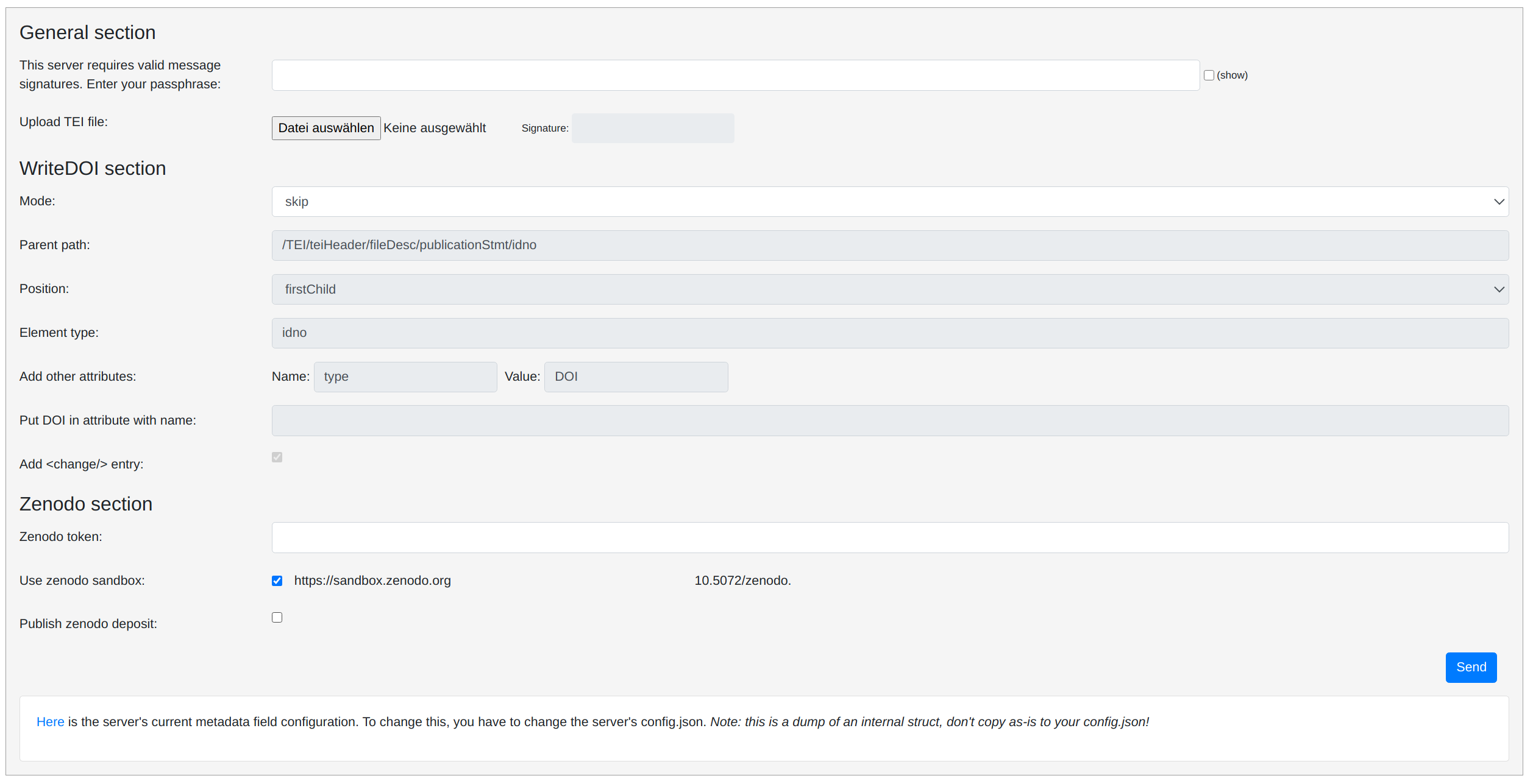
Manual mode
Besides being responsive to github webhooks, the server also has a nice web form that you can use to upload a TEI file. It will then do its magic on the file – extract metadata, get DOI, add DOI if this is requested – and upload/publish it at zenodo. If the file was modified in the process, the changed file will be the response of the service, so that you can download and save it to your computer. (If the file was not changed the response will simply be the deposit’s DOI.) What is its configured behaviour in the webhook setup can be controlled via the form in this „manual“ scenario: Different switches and variables affecting the „add DOI into TEI“ step, publish or not the deposit in the end, etc. Most importantly, it requires the web visitor to enter their valid zenodo (sandbox) personal access token.
While this is planned for the future, as of now the service does not allow you to specify the patterns used to extract the metadata, but is bound to the patterns specified in the server’s configuration. Near the bottom of the form, you show these patterns and check whether or not they fit your TEI files. It is also recommended to study the service’s Readme for more detailed information about the individual configuration options.
A public instance
At one point, I had the impression that when they hear „Hey, here’s a service for you“, many people don’t expect a server software providing a service that they have to deploy and run themselves. People rather expect a server someone else is running, available for the public; and understandably so. However, this particular service takes its input and performs a request at a third party – zenodo – with it. So I was somewhat hesitant to simply open it up. Anyway…
For the time being, I have indeed opened up an instance of the service to the public at http://c106-211.cloud.gwdg.de:8081/. I am doing this in the hope that it will encourage people to test the service and give feedback. So I invite everyone who is interested to give it a try and see if it fits their needs (if the metadata extraction patterns fit your TEI files), needs some particular things yet to be worked on etc.
To add another modicum of security, the service requires signed messages both in its webhook and in its manual usage scenario. To sign messages, you have to use a passphrase that is defined in the server’s configuration file. For the public instance, this is „ThIs_iS_A_BeTtEr_sEcReT!!“ (without the quotes).
Depending on how this is used (how frequently, how successfully etc.), the public instance may be discontinued at any time, but you will still be able to download the software from its development home/releases page.
I count on you not to use it for malevolent purposes. In particular, please consider using zenodo’s sandbox instance rather than the „real“ zenodo repository. (There is a checkbox at the bottom of the form which defaults to the sandbox.)
On the other hand, be aware that in this initial phase of the software launch, extensive logging as seen above, is done, so your IP address and even your zenodo (sandbox) personal access token will be included in the logs on the server. This is not used for anything other than debugging in case of problems and deleted after two weeks. The TEI files themselves are not saved.
Future steps
Here’s what I have in mind as next steps:
- I would like to add a validation step that runs before everything else; otherwise, rolling everything back and forth on github/zenodo is no fun…
- The webservice should be made more reliable and convenient for non-institutional (i.e. public web form usage) setup, e.g.
- the configuration of metadata extraction patterns should also be possible via the web form interface,
- On errors, some form of notification should be sent;
- Handling of files with XIncludes (which we are using to code multi-volume works; while I could have resolved them into big single files I have skipped them for now and will come back when I have an idea how to make a deposit with all files needed);
- Add gitlab support.
On the other hand, besides further development of the t2z service, our web application does not yet reflect the DOIs that we have. We should decide about how to include this in our citation suggestions and catalogue view. Vice versa, we could maybe provide better pointers to the web presence and the collection as such at zenodo’s end…
I would be happy to hear about your ideas about and experiences with this piece of software! You can give feedback either by commenting here at the blog, via mail to Andreas Wagner, twitter @anwagnerdreas or create an issue at the project’s gitlab site (which will require you to create an account with the GWDG).
That’s it for today, so long, and remember: Be FAIR, strive for long-term archival, and have FUN!
