The fundamental importance of the School of Salamanca for the early modern discourse about law, politics, religion, and ethics is widespread among of philosophers and legal historians. These early modern texts extend beyond the core authors, and serve to analyze the history of the Salamanca School’s origins and influence, as well as its internal discourse contexts within the context of the future dictionary entries.
Especially on the topic of dictionaries, the idea to test and explore our corpus with modern NLP applications came up in the project a long time ago. We often asked ourselves which lemmas or information we could find with help of a text analysis, and above all how complex this realization would be with our data. Thus, in 2021 we started a natural language processing task (word frequency distribution) by using the Python programming language to explore our corpus and establish groundwork for further text mining.
Inhaltsverzeichnis
Corpus description
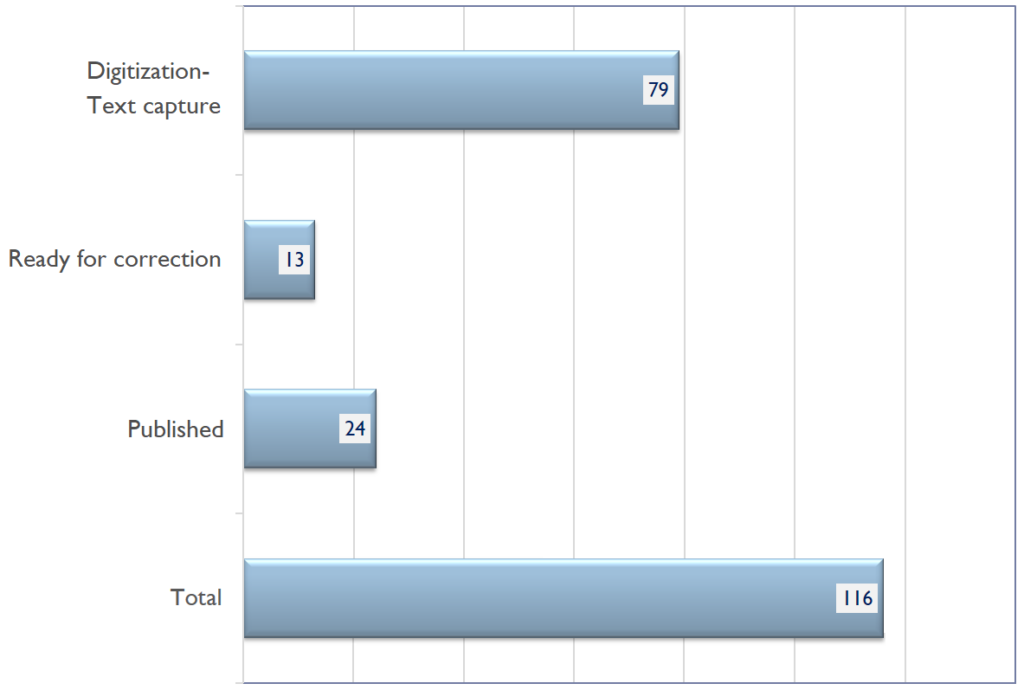
The digital collection of the School of Salamanca consists of 116 works in early modern Latin and Spanish, available in 16th- and 17th-century prints.
Regarding the stage of text edition, the corpus had 79 works in process of digitization and text capture; 13 works were in part automatically corrected and awaiting a manual scholarly correction; 24 works were as full-text published online. It means, they went through a manual scholarly correction and editing consisting of correcting erroneous transcriptions, original printing errors, and above all resolving brevigraphs and word separations, which were not automatically corrected. Although these last group of works consists one-fifth of the whole corpus, their content (e.g., author selection, topics, and structures) served as solid data representation for our analysis.
As a result, we compiled 24 works (14 in Latin and 10 in Spanish) as our input dataset for the NLP task.
We also classified the works by discipline and for technical reasons by language, since the tools are language dependent. This process yielded to the following three groups: Civil Law, Canon Law and Theology.

These published texts are available in two reading views; in a diplomatic form (close to the original source text) as well as in a constituted (normalized) form, which also presents the expansions made by the scholar editors (see Vitoria, Confessionario both in diplomatic and constituted view). Therefore, the constituted view was chosen as a more suitable version, which simplifies text processing with current libraries. Lastly, we compile the selected texts in plain text (TXT) format directly from our website.
NLP applications
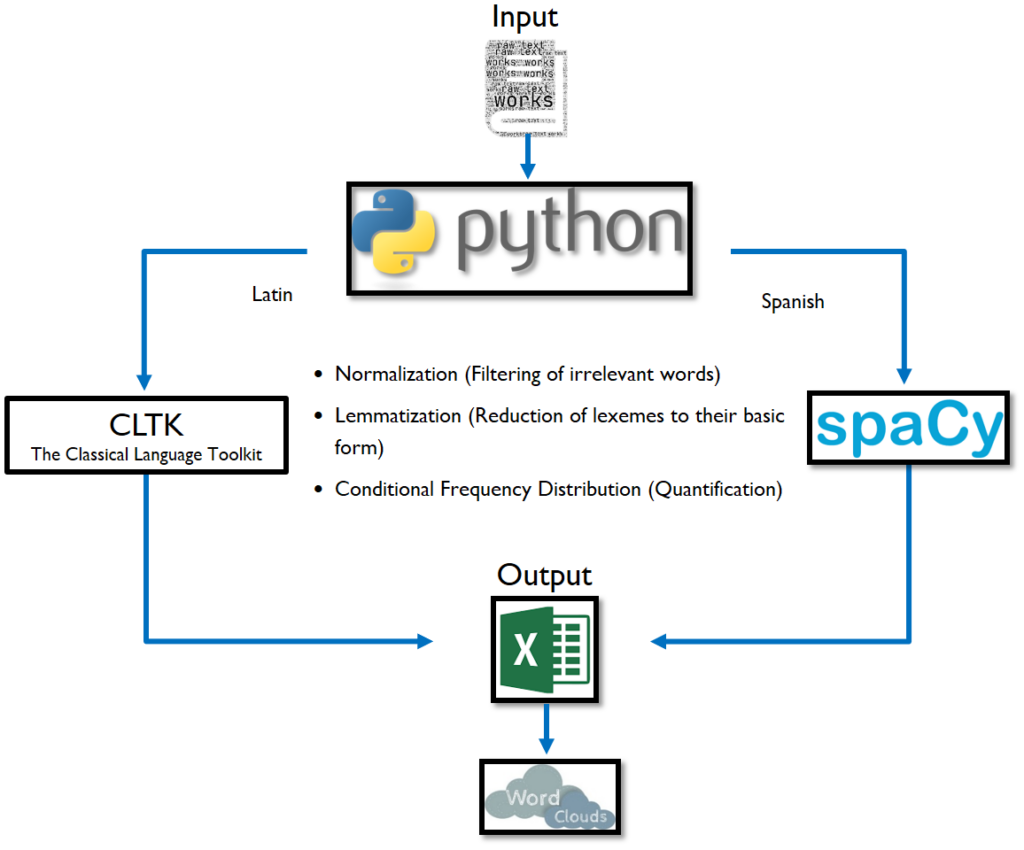
As above mentioned, our dataset was composed by 14 Latin and 10 Spanish works, which were processed with two different python libraries, namely, CLTK (Classical Language Toolkit) for Latin and spaCy for Spanish. Unfortunately, CLTK does not yet provide a module to process early modern Spanish; that is why, spaCy was selected as the best alternative for this text analysis. Even though it is used to process modern languages, the use of spaCy modules has shown to be very helpful for diverse NLP (Natural Language Processing) tasks.
Three important steps compose our analysis approach: normalization, lemmatization, and conditional frequency distribution (see image Steps of our NLP analysis).
In normalization, the dataset is cleaned from stop words, stripped of unnecessary characters (e.g., “\n”, empty spaces, or irrelevant numbers). This process depends on text structure and its language representation. As a matter of fact, the cleaning process applied on our Latin and Spanish collection was adapted based on the above-mentioned criteria. For instance, we created our own stop word lists for both, Latin and Spanish, taking into account our specific text phenomena: numerals, one letter references, paragraph marks (pilcrow ¶), etc.
In the Latin dataset, it was necessary to replace the letters J/j by I/i and V/v by U/u and to remove accents or macrons, thus improving word reduction to definite base form in the lemmatization process . Similarly, filtering words was an important normalization phase in both datasets. Ruling out words that comprise just one letter, enabled the program to focus on meaningful lexemes, whose length is composed of two or more letters, and ignore irrelevant words and unimportant characters. The following function describes the process.

After normalizing both datasets, the second step was lemmatization, in which each lexeme is reduced to its base form (e.g., obligado –> obligar, iuris –> ius). As above mentioned, two different lemmatizers were used for this process. On the one hand, LatinBackoffLemmatizer for Latin, and on the other hand, spaCy Lemmatizer for Spanish texts, which we adapted to work with some word variations of the early modern Spanish.
Lastly, we reached the most essential step of our approach: the quantification phase, namely, conditional frequency distribution. After extracting the lemma of each token, we calculated the occurrences of each of them in the text, for example, the lemma ius appears 22217 times across the whole Latin dataset. We focused on the top 100 lemmas with the highest frequency, which represents the level of importance inside the data collection.
The output of our results was stored in an Excel spreadsheet, since it is a well-known format, which allowed our interdisciplinary team to use it, in case we wanted to conduct further analysis. For more technical details about the Python code, and the results are posted on GitHub.
Results
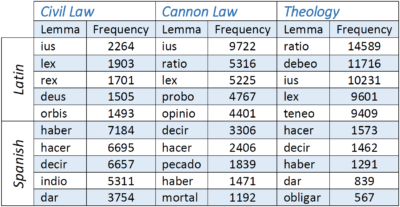
We obtained six lists (every list is associated to its discipline and language), each containing the top 100 most frequent lemmas. The list structures present an ID, which indicates the ranking position of the lemma, lemma frequency (it displays the number of occurrences of the lemma inside the text) and lexeme column. To enable a better visualization here, the lexemes were excluded, and only the first five lemmas and their frequencies are presented respectively. See results in GitHub. In addition, we produced two more lists, a Top-100 list pro language, to have a general view of the corpus. And last but not least, as visualization, we employed word clouds to represent the results of these word frequencies.


Challenges and Outlook
Working with early modern works brought up challenges during the process. Regarding lemmatization in Spanish, as spaCy’s model is based on modern Spanish, it was necessary to group lexemes with spelling variations to a specific lemma (iglesia/yglesia –> iglesia). Thus, the program calculated the frequency correctly. Similarly, in Latin, the JVReplacer normalized certain lemmas, since the Latin alphabet does not distinguish between J/j and I/i and V/v and U/u (usura/vsura). Fortunately, this model was already available in CLTK.
On the other hand, our corpus contains mixed language texts. It means, the main language is Latin; however, there are quotations or marginal notes in Spanish and vice versa. Working with the selected corpus did not show a great difference, since these passages were short. Nonetheless, it is a task to be solved, as we will edit texts containing a significant mixture of both languages (long glosses written in Latin, whereas the main text is written in Spanish. See Alfonso de León & Gregorio López: Las Siete Partidas. (Mehrbandwerk)).
Another factor that may influence the general quantification, is the difference in the size of the texts in our heterogeneous corpus. Two of our works can illustrate this case: Vitoria’s Confessionario is 47 pages long, whereas Politica Indiana is 1190.
A future challenge may present itself in the expansion of our digital collection. As a matter of fact, the more works that are added to our data collection (which is highly expected), the longer it will take to process them. That is why, we are currently working on developing and updating our NLP methodology to process faster and efficiently larger amount of texts, in order to not slow down the code run time.
In the future, we would like to conduct further analysis with diverse NLP applications, such as NER (Named Entity Recognition), POS tagging (Part-of-Speech), or implementing our methodology with the application of softwares for text analysis.
List of Works
- Vitoria, Confessionario (2018 [1562]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0015>
- Castillo, Tratado de Cuentas (2018 [1522]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0004>
- Vitoria, Relectiones Theologicae XII (2018 [1557]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0013>
- Las Casas, Treinta Proposiciones (2018 [1552]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0034>
- Vitoria, Summa Sacramentorum (2018 [1561]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0014>
- Azpilcueta, Manual de Confessores y Penitentes (2019 [1556]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0002>
- Mercado, Tratos y Contratos (2019 [1569]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0007>
- Solórzano Pereira, Politica Indiana (2019 [1648]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0010>
- Báñez, De Iure et Iustitia Decisiones (2019 [1594]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0003>
- Cano, Relectio de Poenitentia (2019 [1558]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0030>
- Avendaño, Thesaurus Indicus (2019 [1668]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0001>
- Sepúlveda, Apologia pro libro de iustis belli causis (2020 [1550]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0095>
- Nebrija, Lexicon Iuris Civilis (2020 [1537]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0078>
- Soto, De Iustitia et Iure (2020 [1553]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0011>
- Villalón, Provechoso tratado de cambios y contrataciones de mercaderes y reprovación de usura. (2020 [1541]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0113>
- Vacca, Expositiones locorum obscuriorum et Paratitulorum in Pandectas. (2020 [1554]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0103>
- Albornoz, Arte de los contractos (2020 [1573]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0017>
- Carrasco del Saz, Tractatus de casibus curiae. (2020 [1630]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0033>
- Freitas, De Iusto Imperio Lusitanorum Asiatico (2020 [1625]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0046>
- Covarrubias y Leyva, Opera Omnia (2021 [1571]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0006>
- León Pinelo, Confirmaciones Reales de Encomiendas (2021 [1630]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0061>
- Solórzano Pereira, De Indiarum Iure ( [1629]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0096>
- Pedraza, Summa de casos de consciencia (2021 [1568]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0083>
- Díaz de Luco, Practica criminalis canonica (2021 [1554]), in: The School of Salamanca. A Digital Collection of Sources <https://id.salamanca.school/texts/W0041>