Der Inhalt wird in der Standard-Sprache dieser Website angezeigt. Sie können einen Link anklicken, um zu einer anderen verfügbaren Sprache zu wechseln.
Textual sources from the early modern period pose specific challenges with regards to their digital acquisition, analysis, and representation. First, the full-text digitization of sources is elaborate and time-consuming, and it still is far away from being fully automatable in a way sufficient to the needs of scholarly researchers. Second, the digital analysis of such data relies on specific historical and textual data models and ontologies and needs to be conducted, on the one hand, through time-consuming scholarly studying and manual annotation of the texts; automatic applications, on the other side, face a significant shortage of natural language 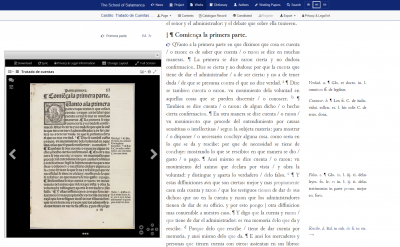 processing tools applicable to „low-resourced“ languages such as early modern Spanish or Latin, or of linguistic and semantic resources appropriate for these specific periods and languages. Finally, while discussions about (textual) data representations and visualizations lie at the very heart of current digital humanities endeavours, there still is only rudimentary consensus about best practices in representing early modern texts and data in all their (multimedial/multimodal) variety in digital forms, as well as about their versioning, forms of readerly participation, underlying software architectures, etc.
processing tools applicable to „low-resourced“ languages such as early modern Spanish or Latin, or of linguistic and semantic resources appropriate for these specific periods and languages. Finally, while discussions about (textual) data representations and visualizations lie at the very heart of current digital humanities endeavours, there still is only rudimentary consensus about best practices in representing early modern texts and data in all their (multimedial/multimodal) variety in digital forms, as well as about their versioning, forms of readerly participation, underlying software architectures, etc.
Some methods and infrastructures that address these challenges are well-known: For instance, the acquisition of historical (text) data may be enhanced through forms of crowdsourcing and collaborative digital editing and technically facilitated by collaborative annotation tools; linked open data models and related infrastructures aim to provide means for annotating data in a way conforming to interoperable, semantic web standards. But also, there is an ever-increasing amount of specific linguistic and geographic resources as well as tools tailored by and for individual early modern research projects – projects that could potentially benefit through communicating and exchanging their resources and tools. In order to strengthen the community-driven use of already existing frameworks and tools, and to communicate methods and tools that were hitherto unknown outside specific use cases, an exchange of theoretical as well as methodological and practical knowledge about digital approaches to early modern historical questions seems crucial.
With the aim of enabling such an exchange on an interdisciplinary and, in a way, also intercultural scale, the Max Planck Institute for European Legal History and the project „The School of Salamanca: A Digital Collection of Sources and a Dictionary of its Juridical-Political Language“ organize a workshop with digital humanities experts from Latin America and Europe. The workshop will comprise a small number of individual project presentations as a common ground for in-depth, hands-on discussions about technical tools, methods and frameworks as well as about (linguistic, geographical, ontological, etc.) resources for the study of early modern sources and contexts.
Date: 23 October 2018
Place: Instituto Max Planck Argentina – Instituto de Investigación en Biomedicina de Buenos Aires, C1425FQD, Godoy Cruz 2390, Buenos Aires
The workshop will be held in Spanish, although contributions may be in English as well.
For registration, please contact us until 15 October 2018 at: salamanca@rg.mpg.de.
Program
14:00 Thomas Duve: Welcome
14:05 Andreas Wagner / David Glück: Introduction
14:15 Andreas Wagner: Digital Humanities Research Related to Ibero-America at the Max Planck Institute for European Legal History
14:45 David Glück: Methods, Frameworks, and Linguistic Resources in the Digital Edition of „The School of Salamanca“
15:15 Discussion
15:30 Hands-On Session: Frameworks, Methods and Tools for Digital Early Modern History
16:30-17:00 Coffee Break
17:00 Gimena del Rio Riande, Romina De León, Nidia Hernández (HD CAICYT Lab, CONICET): Integrating annotation, digital edition tools and GIS resources: Practical experiences from the LatAm project (project presentation and hands on session)
18:00 Discussion
18:30 Closing of the Workshop and Farewell


 Since its beginning in 2013, the Salamanca Project has been developing a text editing workflow based on methods and practices for sustainable and scalable text processing. Sustainability in text processing encompasses not only reusability of the tools and methods developed and applied, but also long-term documentation and traceability of the development of the text data. This documentation will provide an important starting point for future research work. Moreover, the text preparation must be scalable, since the Digital Source Collection comprises a relatively large mass of texts for a full-text digital edition project: in total, it will involve more than 108,000 printed pages from early modern prints in Latin and Spanish, which must be edited in an efficient and at the same time quality-assured manner.
Since its beginning in 2013, the Salamanca Project has been developing a text editing workflow based on methods and practices for sustainable and scalable text processing. Sustainability in text processing encompasses not only reusability of the tools and methods developed and applied, but also long-term documentation and traceability of the development of the text data. This documentation will provide an important starting point for future research work. Moreover, the text preparation must be scalable, since the Digital Source Collection comprises a relatively large mass of texts for a full-text digital edition project: in total, it will involve more than 108,000 printed pages from early modern prints in Latin and Spanish, which must be edited in an efficient and at the same time quality-assured manner.
