Ein Bericht von David Glück und Andreas Wagner
Am 1. März 2018 wurde die Version 1.0 der Webanwendung im Rahmen eines Beitrags von Andreas Wagner und David Glück bei der Konferenz „Digital Humanities im deutschsprachigen Raum 2018“ als freie Software veröffentlicht und der wissenschaftlichen Community zur Verfügung gestellt. Seitdem wird die Webanwendung in Open Source und mit einem laufenden Versionierungsmodell weiterentwickelt. Sowohl die Webanwendung als Ganze als auch die einzelnen Releases der Anwendung sind seitdem nachhaltig archiviert und über DOIs zitierbar.1 Ebenfalls 2018 wurde die auf der Webanwendung aufbauende Digitale Quellensammlung des Projekts erstmals einem fachwissenschaftlichen Publikum präsentiert und (in Verbindung mit der Publikation von Francisco de Vitorias Confessionario, des ersten Textes der Digitalen Quellensammlung) als Forschungsplattform veröffentlicht. Im März 2020 haben wir die Version 2.0 der Webanwendung veröffentlicht. Im Folgenden wollen wir einen Überblick über die wichtigsten Entwicklungen seit der erstmaligen Veröffentlichung geben.
Table of Contents
1 Hintergrund: Versionen und Releases der Software
Seit der Veröffentlichung unter der freien MIT Lizenz findet die gesamte Entwicklung der Webanwendung in öffentlich zugänglicher Form statt. Hierfür wurde der Programmcode im Rahmen der Veröffentlichung aus dem projektinternen Versionskontrollsystem in ein öffentliches Repositorium auf der Software-Entwicklungsplattform GitHub überführt. Alle Änderungen am Programmcode im Rahmen der Weiterentwicklung, der Hinzufügung neuer Features der Webanwendung oder auch der Fehlerbehebung werden über das GitHub zugrunde liegende git-Versionskontrollsystem protokolliert und einsehbar. GitHub bietet darüber hinaus ein Projektmanagement-System, in dem z.B. Tickets für gewünschte Features oder zu behebende Fehler erstellt und verwaltet werden und das die Definition von Entwicklungszielen für zukünftige Programmversionen erlaubt.2 Durch die öffentlich zugängliche, umfassende Protokollierung der Code-Modifikationen und des Managements der Entwicklung sollen sowohl Dokumentation als auch Transparenz in der Entwicklung gewährleistet und somit eine Nachnutzbarkeit der Webanwendung (bzw. einzelner Module, Code-Schnipsel usw.) auch in anderen Projektkontexten erleichtert werden.
Ein weiterer, für den Forschungsprozess sehr wichtiger Aspekt ist die Möglichkeit der langfristigen Speicherung und zitierbaren Veröffentlichung von Programm-Releases in Verbindung mit der automatisierten Archivierung der Releases durch die Open Access-Plattform Zenodo. Hierfür nutzt das Projekt einen gemeinsam mit der Digitalen Akademie entworfenen Veröffentlichungsworkflow: Sobald alle Änderungen für eine neue Version durchgeführt sind, wird bei GitHub der Release einer Version durchgeführt (z.B. der Version 1.5.1 der Webanwendung). Dabei wird zugleich und automatisch eine Veröffentlichung für die Programmversion bei Zenodo erstellt, die neben Downloadmöglichkeiten auch einen Zitiervorschlag für die Software-Version sowie eine persistente ID in Form einer DOI-Nummer angibt. Durch die persistente Versionierung und Referenzierbarkeit der Software auf diese Weise bekommt die Webanwendung – neben den Vorteilen der Nachhaltigkeit und Dokumentation – auch eine „greifbare“ Form als laufende wissenschaftliche Publikation.
2 Modularisierung (Daten und Microservices)
Ein zentrales Bestreben in dieser Phase der Entwicklung richtete sich auf eine verbesserte Trennung der einzelnen Datentypen und Programmmodule in der Webanwendung. Während die Webanwendung in ihrer anfänglichen Komposition gewissermaßen einem „monolithischen“, Daten und Anwendungslogik vereinenden Architekturmodell folgte, zeichnete sich bald die Notwendigkeit einer deutlicheren Trennung von Anwendung und Daten ab, um mit den steigenden Textgrößen, wachsenden Datenmengen und Bearbeitungszeiten für die Ableitung von Daten aus dem TEI-Format adäquat umzugehen. Nach und nach wurden zwei Pakete für Forschungsdaten aus der ursprünglichen Webanwendung extrahiert und als eigene „Apps“ für die eXist-Datenbank definiert:
2.1 Primärdaten
Das Paket der im TEI-Format vorliegenden Primärdaten enthält die offiziell publizierten TEI-Daten, die letztendlich aus dem umfangreichen Prozess der Textaufbereitung resultieren. Wann immer eine neue oder überarbeitete TEI-Version eines Werkes (und zukünftig auch eines Autorenartikels oder Wörterbucheintrags) publiziert wird, werden die gesamten TEI-Daten paketiert und als Daten-App in eXist-db importiert.3
2.2 Sekundärdaten
Das Paket der von den TEI-Daten abgeleiteten Sekundärdaten (HTML, RDF, Plain Text usw.), die projektintern auch als Webdaten bezeichnet werden. Die Ableitung dieser Daten aus dem TEI-XML kann für größere Texte mehrere Stunden (pro Text) betragen; eine Aussonderung dieser Daten ermöglicht einen Workflow, bei dem TEI-Daten nur noch einmalig prozessiert und die abgeleiteten Webdaten daraufhin exportiert werden, sodass sie bei jeder Neuinstallation der Webanwendung auf einem Server nur noch importiert (und nicht mehr neu generiert) werden müssen. Durch die so bewirkte Minimierung des Rechenaufwandes „skaliert“ die Webanwendung und bleibt installier- und einsetzbar auch im Hinblick auf zu erwartende Textmengen, die den gegenwärtigen Umfang der Digitalen Quellensammlung erheblich erweitern werden. Außerdem hat sie den Prozess der Entwicklung und des Deployment der Webanwendung stark beschleunigt, da diese nun zu Testzwecken schnell und ohne die zeitintensive Neugenerierung von Daten installiert werden kann.
2.3 Factory vs GUI
Auch auf der Code-Seite haben wir eine deutlichere Trennung zwischen Datenverarbeitung und Präsentation eingerichtet. So wurden aus der organisch gewachsenen Struktur Programmteile, die für das Benutzerinterface, für die API (s.u.) und für die Generierung der abgeleiteten Datenformate zuständig sind, in getrennte Dateien verlagert (modules/gui.xqm, modules/api/*, modules/factory/*).
2.4 Microservices
Insgesamt wird die Anwendung sukzessive auf sog. Microservices umgestellt, d.h. die Anwendung wird funktional ausdifferenziert und einzelne Funktionen werden als eigenständige Dienste implementiert, die untereinander in sprach- und implementierungsunabhängiger Weise kommunizieren. Die “interne” Kommunikation zwischen diesen Diensten, aus deren Zusammenspiel sich die Gesamtfunktionalität der Webanwendung ergibt, wird, wo immer möglich, nach offenen Standards implementiert. Beispiele sind die Suchmaschine, die unter http://search.salamanca.school/ einen von der Benutzeroberfläche getrennten Dienst anbietet, auf den die Webanwendung im Hintergrund über das OpenSearch-Protokoll zugreift, oder der Bildservice, der gemäß dem iiif-Protokoll4 unter https://facs.salamanca.school/iiif/image bzw. https://facs.salamanca.school/iiif/presentation Bild- und Bildmetadaten anbietet und auf den generische Bildbetrachter wie Mirador (dieser ist in die Bildansicht der Webanwendung integriert), UniversalViewer oder andere5 zugreifen können. RDF-Daten liefern wir im Moment unter https://api.salamanca.school/v1/texts/W0002?format=rdf aus und verarbeiten sie im Präsentations-Code der Webanwendung, wir sind allerdings in den Aufbau der Plattform lod.academy mit einbezogen, so dass wir die Auslieferung und Abfrage solcher Daten demnächst über die SPARQL-Abfragesprache realisieren wollen.
Dies sind die Vorteile einer Microservices-basierten Architektur:
- Ein Fehler in einem Dienst bleibt isoliert, während die übrigen Dienste weiter ansprechbar sind. (Ob Funktionalitäten wie die Benutzeroberfläche, die mehrere Dienste kombinieren, weiter zur Verfügung stehen, hängt allerdings natürlich von der jeweiligen besonderen Konstellation ab.)
- Die Dienste können auf mehrere Rechner verteilt werden und so die Last des Gesamtsystems aufteilen. (Es kann sogar ein besonders beanspruchter Dienst selbst in lastverteilter Weise, d.h. auf mehreren Servern angeboten werden.)
- Das Update eines solchen Mikrodienstes kann erfolgen, ohne die gesamte Anwendung updaten (und offline nehmen) zu müssen.
- Ein Dienst kann leicht ersetzt werden, wenn er mit einer anderen Software effizienter, stabiler oder sicherer implementiert werden kann, oder wenn die Software nicht mehr weiter entwickelt wird.
- Auch andere Projekte können auf Teilfunktionalitäten der Salamanca-Software zugreifen (z.B. die Suchmaschine in die Browserleiste integrieren oder eine eigene virtuelle “Ausstellung” von Facsimiles definieren und präsentieren).
Dieses System von Präsentations- und Datenverarbeitungssschicht, die jeweils auf verschiedene Microservices zurückgreifen, umfasst also mehrere Anwendungs- und Datenserver, u.a.
-
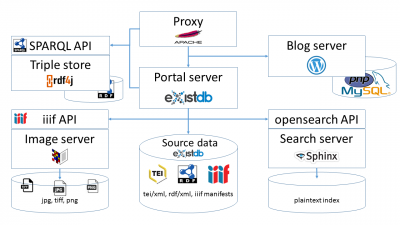
Diagramm der Service-Infrastruktur die eXist-Datenbank mit einem eigenem Jetty-Anwendungsserver,
- den Sphinx-Suchserver,
- den Digilib-Bildserver,
- einen Apache Any23-Service für die standardisierte Generierung und ein Eclipse RDF4J Service für die Auslieferung und Abfrage der RDF-Daten.
Diese Server sind wiederum von einer Vielzahl von Laufzeitumgebungen und Linux-Betriebssystempaketen abhängig und daraus ergibt sich der Hauptnachteil dieser Architektur: Eine erhöhter Overhead für die internen Kommunikationen und eine höhere Komplexität bei der Installation und Wartung des gesamten Ökosystems. Daher haben wir einige Energie in die Steigerung der Automatisierbarkeit von Installation und Wartung investiert (s.u. unter Punkt 4. Deployment).
3. Einzelne Erweiterungen und Verbesserungen
3.1 Zitationen und Nachweise
Wir bieten nun fachgerechte Zitiervorschläge sowohl auf den Katalog-Seiten als auch in der Lesansicht der Werke (unter “Export” sowie für die einzelnen Abschnitte hinter dem jeweiligen, über das Hand-Icon “☞” zugänglichen Kontextmenü) an. Diese beinhalten neben Autor, Titel und Veröffentlichungsdaten auch einen Permalink auf das Werk und das Abfragedatum. (Im Falle der abschnittsweisen Zitation wird statt des generischen Permalinks die formatgenaue Zitation verwendet, also unter Angabe des HTML-Formats. Ob hier darüber hinaus noch aktive Optionen wie der Textmodus (konstituiert/diplomatisch), ein geöffneter Bildbetrachter oder ein aktiver Suchbegriff aufgenommen werden sollten, um die präzise Ansicht zitieren zu können, müsste erst noch diskutiert werden.)
Die über die Katalogseiten zugänglichen Metadaten der Werke weisen nun differenzierter die Rollen von fachwissenschaftlichen und technischen Bearbeitern sowie der Reihenherausgeber aus. Umgekehrt finden sich auf den individuellen Projektbeteiligen-Seiten Aufstellungen der Werke, an deren Redaktion die jeweilige Person beteiligt war.
3.2 Downloads
Auf der Katalogseite der Werke (und z.T. auch in der Leseansicht unter “Export”) werden Daten zum jeweiligen Werk in diversen Formaten angeboten: Die TEI/XML-Quelldaten, der extrahierte Plaintext (entweder in der konstituierten oder der diplomatischen Fassung), der teiHeader aus den Quelldaten, das iiif Manifest und die RDF-Daten. Im Bildbetrachter gibt es eine Download-Option für eine Zip-Datei mit allen Bilddigitalisaten, auf der Werkübersichts-Seite kann die gesamte Sammlung gezippt im XML- oder TXT-Format heruntergeladen werden. Dort gibt es auch erste statistische Angaben zum Gesamt-Korpus (per 16.03.2020: 29.420 digitalisierte Faksimiles, 6.110 im Volltext digital edierte Druckseiten, 3,9 Mio. Tokens, 143.744 Wortformen).
3.3 Diverse “interne” Updates
Wir haben aus Performancegründen eine Reihe von Änderungen und Updates vorgenommen. Nach unserem Eindruck sollte die Webanwendung dadurch wesentlich responsiver und stabiler sein.
- Die meisten Transformationen, die bisher durch XSLT durchgeführt wurden, werden jetzt in xQuery Typeswitch-Anweisungen durchgeführt. Dies erspart den Aufruf des externen (Saxon-)Prozessors für das Abarbeiten der XSLT-Skripte, und es erlaubt die parallele Verarbeitung verschiedener Schritte sowie den Zugriff auf die von eXist-db verwalteten Indices, was für eine Performance-Verbesserung sorgt.
- Die Anfragen an externe Dienste und eigene Microservices wurden vom eXist-db-eigenen auf den EXPath httpclient umgestellt. Dies reduziert die Abhängigkeit von proprietären Software-Bibliotheken und bietet größere Stabilität und Effizienz.
- Wir haben die API und einen Teil der Webanwendung von einer if-else-Struktur in der zentralen Routing-Seite auf den RESTXQ-Mechanismus umgestellt. Dies erlaubt eine stärker deskriptive und implementierungsunabhängige Spezifikation der Schnittstellen, was zu einer besseren Wartbarkeit und konsistenteren Systemarchitektur im Ganzen führt.
- Die Webanwendung läuft auf der jetzt aktuellen Version (Stand: 2020-03-16) von eXist-db (5.2) und Ubuntu (18.04). Auch dies bringt Performance- und Stabilitätsgewinne und stellt die zeitnahe Verfügbarkeit von Patches bei Problemen sicher.
4. Deployment (Installation und Wartung)
Um die vielfältigen Abhängigkeiten zu dokumentieren und die Installation der Software-Module weitestgehend zu automatisieren, wurde die Installation der Infrastruktur unter Mithilfe der Digitalen Akademie programmatisch in Form von Skripten definiert, die sich mit dem quelloffenen Automatisierungstool Ansible ausführen lassen. Dabei wird für jede relevante Software ein eigenes Modul definiert, das bestimmte Abhängigkeiten der Software und des Moduls von anderen Modulen sowie die für die Installation der Software notwendigen Schritte definiert. Ein sogenanntes Playbook kombiniert dann die diversen Module für verschiedene Szenarien (z.B. Test- oder Produktionsserver, Webserver oder Bildserver). Durch diese weitgehende Automatisierbarkeit verringert sich nicht nur die für die Installation eines Server-Systems benötigte Zeit erheblich; zugleich wird die IT-Infrastruktur replizierbar und damit auf ein nachhaltigeres Fundament gestellt. Da diese Skripte zum Teil Informationen wie Benutzernamen oder Ports enthalten, werden sie allerdings nicht publiziert, um die Sicherheit der laufenden Systeme nicht zu gefährden.
3 Aktuell werden die die Primärdaten-Pakete nur projektintern verwaltet und nicht in gesammelter Form archiviert. Statt dessen werden Zug um Zug TEI-Dateien einzeln in Zenodo importiert, mit persistenten Identifiern versehen und publiziert/archiviert. Angedacht ist hier die Entwicklung eines zum beschriebenen Software-Release-Zyklus vergleichbaren Automatismus. Dies ist allerdings noch nicht abgeschlossen. Der Vorteil des Ansatzes, einzelne Werke (und nicht das Paket aller Werke) als die relevanten Datensätze zu verwalten, die individuell persistent adressiert und archiviert werden, liegt auf der Hand. Ein solches Verfahren muss allerdings komplexere, mit jedem Werk variierende Metadaten handhaben können.
4 Eine detailliertere Beschreibung findet sich auf unserem Blog: https://blog.salamanca.school/de/2018/07/05/german-iiif-in-der-schule-von-salamanca/.
5 Aktuell werden auf https://iiif.io/apps-demos/#image-viewing-clients neun weitere Betrachter aufgelistet.