One of the central tools for working with the texts in the School of Salamanca‘s digital collection of sources is our digital edition’s search functionality, which is supposed to provide an easy-to-use means for querying single texts or the whole corpus for search terms. Speaking from a technical perspective, the quality of this search functionality – or, more precisely, the search engine that it is powered by – depends on several resources that it needs to be provided with, such as high-quality dictionaries for the languages in the corpus as well as a suitable setup for the search engine’s ‘indexing’ of the texts. As we recently encountered a demand to adjust the functioning of our search engine in a rather fundamental way due to some specific orthographic properties of the texts we are dealing with, I would like to use this opportunity to give a rough (and, hopefully, not too technical) overview of the functioning of our search before going into detail about the problem at hand.
In the case of our digital edition, the search functionality is currently based on a Sphinxsearch engine that provides our web application with search results in the following way: whenever a user triggers a search (say, for the Latin term “lex”), the web application sends a request to the Sphinxsearch engine (that is, a data server independent from the web application) asking for all text snippets that include the search term, or a term derived from its lemma (such as “leges” or “legum”), or even – if they are available in the engine’s dictionaries – translated forms of the term (hence, in this case, we would also find the Spanish term “ley”). These snippets, which are returned by the search server after it has gone through its indexes, are then displayed in the search results view in our webpage. Of course, this works only if the search server has already indexed these snippets beforehand (where ‘indexing’ generally means the process of storing and making the text snippets searchable), so that it can quickly fetch them on demand. Therefore, whenever a new work is being published in our digital collection, text snippets for the respective work are created through the web application, and a nightly indexing routine of the search server regularly requests all available snippets from the web app, thus making sure that the snippets it holds are updated on a day-to-day basis. As one might already guess with regards to the prevalence of the term ‘index(ing)’ in this paragraph, a suitable configuration of the indexing routine is of central importance for a well-functioning search engine, and it is precisely the configuration of the indexing which we recently had to revise fundamentally due to a problem that we were hinted at by users of the search function.
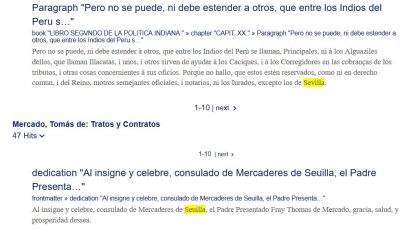 In our Latin and Spanish texts, a frequent orthographic pattern is the interchangeability of certain characters like “u” or “i” such that a word may occur in different forms throughout texts from the same period, or even within the same text, without varying in its meaning. To take a concrete example, it is not unusual in our texts to find a word like “Sevilla” (the city in Spain) also as “Seuilla” or, potentially, even as “Sebilla”. In this example, the interchangeability of characters applies to the characters “v”, “u”, and “b”, but it may also involve other frequently-used character pairings such as “i” and “j” (e.g., “ius” vs. “jus”), as well as some more rarely and, for the modern reader, more unexpectedly occurring pairings such as “j” and “x” (e.g., “dejar” vs. “dexar”).
In our Latin and Spanish texts, a frequent orthographic pattern is the interchangeability of certain characters like “u” or “i” such that a word may occur in different forms throughout texts from the same period, or even within the same text, without varying in its meaning. To take a concrete example, it is not unusual in our texts to find a word like “Sevilla” (the city in Spain) also as “Seuilla” or, potentially, even as “Sebilla”. In this example, the interchangeability of characters applies to the characters “v”, “u”, and “b”, but it may also involve other frequently-used character pairings such as “i” and “j” (e.g., “ius” vs. “jus”), as well as some more rarely and, for the modern reader, more unexpectedly occurring pairings such as “j” and “x” (e.g., “dejar” vs. “dexar”).
The problem with such interchangeable characters, from a search engine’s point of view, is that the engine does not know about their equivalence and thus cannot yield the whole set of search results for certain queries. For example, if a user searches for the above-mentioned “Sevilla” in its modern spelling, the engine will only return results in which the exact character string “Sevilla” occurs, but not strings like “Seuilla” or “Sebilla”.
There are, however, certain ways to cope with this problem. One quick (and, from a system administrator’s perspective, quite lazy) solution would be to advise the user to be aware of this problem and to anticipate it in her search queries. For instance, our search engine allows for the use of ‘regular expressions’ in queries, which makes it possible to replace certain characters by so called ‘wildcards’: in this way, all possible forms of “Sevilla” could be found by using a query string such as “Se?illa”, where the “?” question mark stands for any character. As this “solution” would demand quite a lot of anticipation from the user, who may not be aware of all the pitfalls of early modern orthography, it is not a very good option. In general, we want to facilitate the usage of our digital tools for the user as much as possible, and this certainly includes the search functionality as a central component of the toolset.
A second possible solution, then, would be to extend the dictionaries of word forms that are used to index the text snippets in such a way that for any word form containing one or more interchangeable characters we also add all its different forms to the respective dictionary. Unfortunately, this is practically unfeasable in a manual and “scholarly controlled” way, since our dictionaries of word forms currently hold between 600,000 (Spanish) and over 2,000,000 (Latin) word forms (and counting). Any endeavour to manually add word forms – even if one would only stick to important ones, such as names – would always represent an open-ended task. The only comprehensive and (ideally) complete solution thus seems to be an automatic replacing of word forms, and fortunately, this is where the Sphinxsearch engine offers quite handy configuration options.
In the configuration for the indexing routine, Sphinxsearch allows for the definition of certain directives that can be used to enhance, speed up, or tweak the indexing (and, thus, the searchability of words). In particular, there is a charset_table directive that can be used for stating which symbols should be relevant for the index, and this directive also makes it possible to map characters to other characters. Until now, for example, the character mapping configuration read as follows:
charset_type = utf-8
charset_table = 0..9, A..Z->a..z, a..z, U+C0..U+FF, U+100..U+17F, U+1C4..U+233, U+370..U+3E1, U+590..U+5FF, U+400..U+7FF, U+500..U+8FF
Here, we first declare the “utf-8” encoding (which is one of the prevalent encodings for the nowadays ubiquitous Unicode character set) as the encoding to be applied for indexing text snippets. The charset_table field then determines which characters are relevant for the indexing routine, and, if required, which of those characters shall be regarded as equivalent to other characters. In this setting, for example, we have stated that we consider digits between 0 and 9 as relevant (0..9), and that all capitalized characters are to be treated as lowercased characters (A..Z->a..z) such that a query for the term “Sevilla” will also find the lowercased form “sevilla” (of course, we also need to declare these lowercased characters as relevant for indexing through the , a..z, segment). Furthermore, we have extended the set of relevant symbols by including the Latin Extended A character block (that is, Unicode symbols in the range between codepoints “U+0100” and “U+017F”: U+100..U+17F) and certain parts of other Unicode blocks such as Latin Extended B, Greek and Coptic, etc.
Now, the solution to our problem lies in the possibility of mapping characters to other characters. Similar to the above-mentioned way of mapping capitalized characters to lowercased characters, we can map a character such as “u” to a completely different character such as “v”, thereby evoking the desired effects of character normalization:
charset_table = 0..9, A..I->a..i,J->i,j->i,K..T->k..t,U->v,u->v,V..Z->v..z,a..i,k..t,v..z,U+C0..U+FF, U+100..U+17F, U+1C4..U+233, U+370..U+3E1,U+590..U+5FF, U+400..U+7FF, U+500..U+8FF
What simply was A..Z->a..z (the mapping of all capitalized characters “A-Z” to their lowercased equivalents) in the previous configuration has now become slightly more complicated:
[...,]A..I->a..i,J->i,j->i,K..T->k..t,U->v,u->v,V..Z->v..z,a..i,k..t,v..z,[...]
Here, we first map all capitalized characters “A..I” to their lowercased equivalents, but then we map the capitalized and lowercased “J”/”j” to the lowercased “i” (not “j”). Equally, after mapping all characters between “K..T” to their equivalents “k..t”, we apply a mapping for “U”/”u”, which are both to be treated as “v” by the indexing routine. Like this, we effectively declare “J”/”j” and “i” as well as “U”/”u” and “v” as equivalent characters, thus normalizing j/i and u/v for any search query. Note that the mapping/replacement of characters stated here has effect only for the “internal” indexing of the snippets in the search engine, but does not actually transform the text snippets displayed to the user in the end by any means.
For the time being, we have refrained from defining further normalizations such as with “v” and “b”, or “j” and “x”, since it is not yet fully clear to us what (unexpected) effects such all-encompassing character normalizations might have, especially in “exotic” use cases that we cannot even imagine. In particular, ‘transitive’ normalization effects are something that we still need to experiment with: If “j” and “i” are equivalent and “j” and “x” are equivalent, then “i” and “x” are also equivalent, although “i” and “x” might not have been used in such an interchangeable manner in early modern texts. Therefore, we very much welcome any further suggestions – also beyond the character pairings mentioned here – that we can use for enhancing our search engine further.


 (Talk given at TEI 2022 conference in Newcastle University,
(Talk given at TEI 2022 conference in Newcastle University,  Since its beginning in 2013, the Salamanca Project has been developing a text editing workflow based on methods and practices for sustainable and scalable text processing. Sustainability in text processing encompasses not only reusability of the tools and methods developed and applied, but also long-term documentation and traceability of the development of the text data. This documentation will provide an important starting point for future research work. Moreover, the text preparation must be scalable, since the Digital Source Collection comprises a relatively large mass of texts for a full-text digital edition project: in total, it will involve more than 108,000 printed pages from early modern prints in Latin and Spanish, which must be edited in an efficient and at the same time quality-assured manner.
Since its beginning in 2013, the Salamanca Project has been developing a text editing workflow based on methods and practices for sustainable and scalable text processing. Sustainability in text processing encompasses not only reusability of the tools and methods developed and applied, but also long-term documentation and traceability of the development of the text data. This documentation will provide an important starting point for future research work. Moreover, the text preparation must be scalable, since the Digital Source Collection comprises a relatively large mass of texts for a full-text digital edition project: in total, it will involve more than 108,000 printed pages from early modern prints in Latin and Spanish, which must be edited in an efficient and at the same time quality-assured manner.
