 (Talk given at TEI 2022 conference in Newcastle University, https://zenodo.org/record/7101456)
(Talk given at TEI 2022 conference in Newcastle University, https://zenodo.org/record/7101456)
The topic of this year’s TEI conference and members’ meeting — “text as data” — addressed a growing amount and diversity of textual data produced by the humanities projects. With the increase of data there is also an expanding need for its quality assurance. Several research data projects have already assigned specific teams to tackle the task of standardizing the continuous quality management. I refer, for example, to the task area “Standards, Data Quality and Curation” within the NFDI4Culture consortium, or the KONDA project at the Göttingen State and University Library. The XML data production is in fact a process of a continuous validation, correction, and improvement, involving, inter alia, ODD, RelaxNG, and XML Schemata; custom Python and R scripts; the XSLT, XQuery and Schematron routines integrated into a test-driven development frameworks such as XSpec.
In my talk I addressed a rather unconventional way of testing the TEI data, namely printing it. TEI production workflows frequently presuppose HTML and PDF export, the issue I focused on is the diagnostic value of such prints for the quality control.
Tabla de contenidos
The School of Salamanca project, its production worklow and printing practice
The project «The School of Salamanca. A Digital Collection of Sources and a Dictionary of its Juridical-Political Language» is jointly sponsored by the Academy of Sciences and Literature Mainz, Max Planck Institute for Legal History and Legal Theory and Goethe-University Frankfurt am Main. It aims at creating an online collection of important texts produced by the philosophers, jurists and theologians related to the University of Salamanca — the intellectual center of the Spanish monarchy during the 16th and 17th centuries.
The edition will contain 116 works, including more than 108 000 printed pages of Early Modern Latin and Spanish texts encoded in TEI XML. In addition, we also compose a historic dictionary of approximately 300 essential terms, rendering the importance of the School of Salamanca for the early modern discourse about law, politics, religion, and ethics.
Currently 36 works have completed the production cycle which includes HTML export for online access and full-text search, IIIF Image and Presentation APIs, RDF and TXT export. Recently, PDF output option was also added, and it had a direct impact on our workflow and data quality control. It is now implemented early in the TEI production as a useful diagnostic tool, exposing semantic and structural inconsistencies of the data.
Production workflow
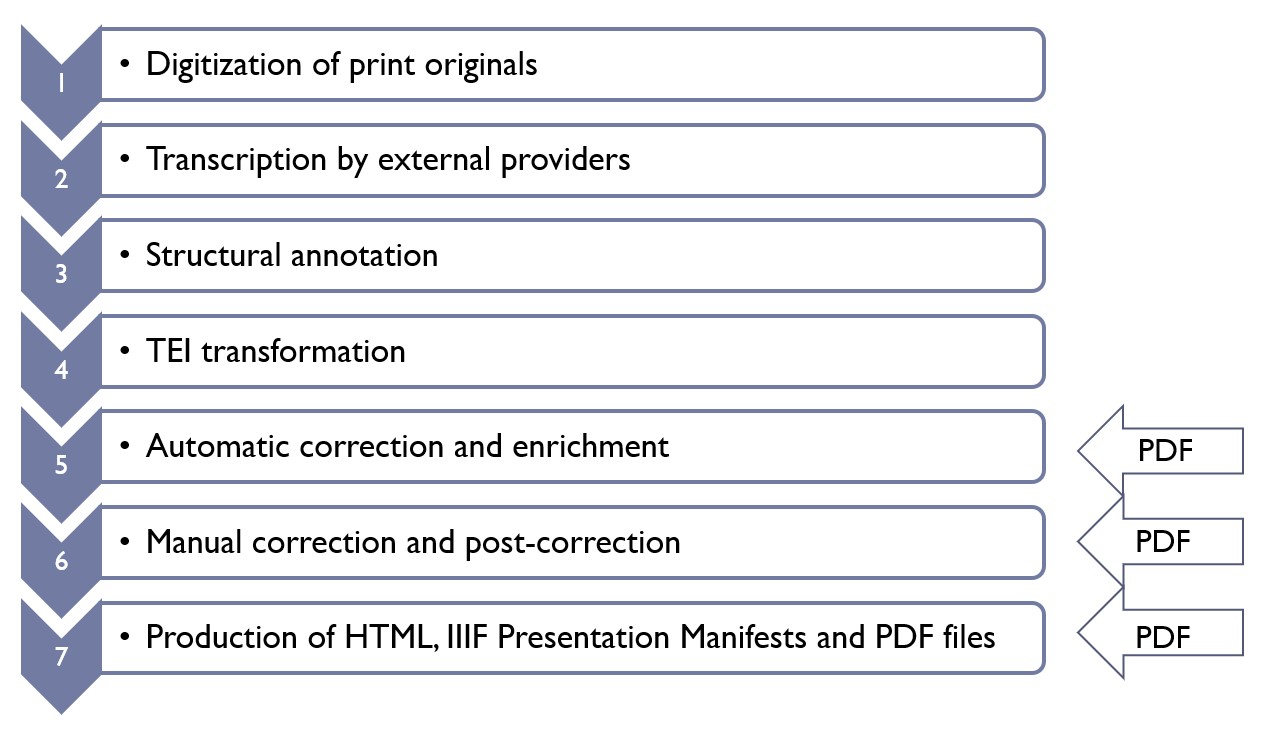
Salamanca’s production workflow consists of a number of steps, which are familiar to those creating Scholarly Digital Editions (SDEs). They were described in detail in a recent blogpost, here is just a summary:

- The first step is the digitization of the print originals held by libraries worldwide. Already at this stage the XML header is compiled for each work with bibliographic metadata and the facsimiles are published on the IIIF Server.
- It is followed by the transcription by the external providers, conducted in TEI Tite format, which, compared to the generic TEI All-Schema, has a reduced, compact vocabulary.
- The TEI Tite files upon arrival undergo the manual structural annotation, cross-referencing and resolution of unclear marks.
- Only after that the text is automatically transformed into a project-specific TEI. The resulting document contains both the metadata in
<teiHeader>, and all elements and attributes adapted to TEI-All. - TEI transformation is followed by a sequence of automatic corrections and enrichment routines, driven by XSLT templates. They apply to the annotation of hyphenated words, abbreviations and special characters resolution and xml:id tagging.
- Then, the texts go to the manual correction and post-correction, where the remaining transcription and typographical errors are resolved.
- The final step is the production and delivery of the derived data formats taking place in the Exist DB. These are HTML pages, IIIF Presentation manifests, Search index and crumb trails, plaintext and RDF data creation, and PDF files.
XSL Formatting Objects
Our printing process works through XSL Formatting Objects (FO) technology. Although the latest XSL-FO 1.1 specification dates back to 2006, this format is still widely used. The reasons might lie in free Apache FO Processor, integrated in Oxygen XML Editor, while its current replacement CSS Paged Media is proprietary. The latest Apache FOP 2.8 was released in November 2022, and its commercial counterparts, such RenderX XEP Engine and Antenna House Formatter, supporting XSL-FO, are regularly updated. At Salamanca we made some preliminary tests with XSL-FO in 2018, and when the production started in 2021, we adopted and upgraded the existing templates. The functionality is not yet fully implemented on Salamanca’s production server, the preliminary PDF output along with the XSL Template can be found in our Github repository.
Book components
In the FO routine the original XML is transformed to XSL-FO document which is then picked up by the Apache FO Processor and converted to PDF. Our task was to create the generic transformation rules, which would apply to all 116 works and render them in print as close to the original as possible. Our template defines nine book components, related to the abstract „page masters” in XSL-FO terminology:
-
- The first component is the so-called “Half title“ or “Schmutztitel”, containing the short title of the work and the name of its author . The second is the “Frontispiece”, rendering the scan of the title page of the original.

- These are followed by the title page of the digital edition and the edition notice.

- Only after that the book contents per se are delivered. First comes the title
page of the original rendered from<titlePage>.

- The introduction section comes next, generated from the
<tei:div>elements
of<tei:front>, followed by the contents of<tei:body>.

- The eighth section delivers the contents of
<tei:back>. The publication concludes with endnotes.

The generic template allows dynamically duplicating or removing the components if, for example, the original contains two title pages (one of the volume series and one of the current volume), or when it lacks the introduction section and the pagination should start from the body.
We do not follow the canons of Western book page design, which places the center of the page area above the center of the page with the gutter margin traditionally narrower than the fore-edge margin. This is because the publication is supposed to be printed or viewed as A4 pages (page-height=»29.7cm» page-width=»21cm»). The XSL-FO “page masters” prescribe three types of margins on each page side, two of which are not printable, and one containing a header (with the work title and the author) and a footer (with page numbers) elements. Here an approximate layout of the page with the dimensions of the top margins:
 It is quite useful to define the print area as a one-cell table, the borders of which can be activated in debugging sessions to control the margins and other layout features.
It is quite useful to define the print area as a one-cell table, the borders of which can be activated in debugging sessions to control the margins and other layout features.
PDF export as a diagnostic tool
PDF production helped us to diagnose some of the XML problems. The XML issues we encountered were of different types and apply to a) the order and the position of elements, b) cross-referencing, c) character encoding, and d) text mark-up.
Order and position of XML elements
Marginal notes and milestones
Marginal notes at Salamanca usually contain two elements – the anchor in the text and the note body itself. The anchors can be alphabetical, numerical, or expressed with a symbol.

Sometimes the anchor is missing in the main text, and the note is just located next to the line it refers to. In XML this corresponds to the position before the <lb> element. The number of marginal notes in one document can be up to 8,000.

A substantial difficulty of displaying non-anchored marginal notes in PDF is conditioned by the fact that in the original they “float” alongside the main text. In XML they are encoded before the line beginning (<lb>), which does not correspond to the line beginning in PDF. Apache FO processor has insufficient support for floats, and the formatters which fully support them, such as Antenna house or RenderX, are proprietary. Considering this, we decided to unify the representation of anchored and unanchored notes – they all get a numerical mark and an anchor in the main text in PDF. In addition, we place all the notes as endnotes in a separate section, creating cross-references between them and anchors.

Milestones have a structure similar to marginal notes – they have an anchor in text and a related mark on the margin, usually an Arabic number. In addition, they frequently have another essential component – an item in the summary which they are linked to.

PDF export highlighted a particular aspect of the encoding of non-anchoted marginal notes and milestones, situated at line end containing a word break. In this case the anchor appears in the middle of the word.
 This case pointed at the usefulness of data visualization even at the stage of data model design. From the print perspective it would be practical to encode marginal notes and milestones not at word break, but before or after the word it refers to.
This case pointed at the usefulness of data visualization even at the stage of data model design. From the print perspective it would be practical to encode marginal notes and milestones not at word break, but before or after the word it refers to.
Title page and its constituents
The PDF printout can be used to test rules regarding the order of XML elements. In this title page, for example, the first paragraph was encoded in the element <byline>, which in all other works follows the title. Correspondingly, it was printed in the wrong position.

Alternatively, an item will not be rendered in PDF if it is located in a different position in the hierarchy than prescribed by the template.
Cross-referencing
The PDF layout is a useful tool for checking the cross-references within the same document. In a given example the item in the “Summary” is lacking cross-reference, but the reason for that was a duplicated milestone number it refers to. This exceptional behavior was a collateral bug of another improvement and was not caught up by Schematron.

The same effect may occur if the reference is made to a separate document, not included in the current publication. This functionality can be implemented in HTML, but in PDF it leads to a missing cross-reference .
The actual design of a reference is another feature which can be tested – namely, which part of the string should serve as an anchor? In the example below two different conventions were chosen for referencing the section of the book from its summary.

Special characters and abbreviations
PDF renders a constituted version of Salamanca TEI encoding, meaning that selected special characters and abbreviations are expanded. We display the standardized versions of characters such as Latin ⁊ (et) and Latin ſ (long s). In addition, Latin, Greek, Hebrew, and Arabic characters occur and need special fonts to be rendered properly. PDF can thus be used as a handy copy-editing and proofreading tool.
Text mark-up
PDF helps to control the uniformity of text mark-up. This can apply to capitalization, italicized script, superscript, initial, and bold parts of the text. In the example below two functionally identical passages had different encodings, the second one marked as header.

PDF export helps to visualize the semantics of the encoding – the aspect which cannot be controlled by the XML Schemata and Schematron.
PDF impact on data quality assurance
PDF creation thus assists the data quality assurance in two ways: on the one hand, it raises formal errors in the code and on the other — it facilitates manual corrections by providing a new «optical impression» of the data where certain kinds of inconsistencies stand out more clear to a human eye. Some of the issues raised depend on the definition of an “error”, which in the context of scholarly digital editions is a rather challenging task. In the classical software world “bug” is a deviation from the desired behavior defined in the software specification (Crispin 2008: 416). The descriptive nature of XML-based digital editions includes an element of ambiguity and interpretation (Wenz, Kesper, and Taentzer 2022). The identification of an error thus requires a skill set which is different from that of a
classical software tester.
I have mentioned above that at Salamanca the steps of the production pipeline are executed sequentially, in a “waterfall” model, where the output of each stage is validated by the respective Schematron file. The final XML is then controlled by the RelaxNG schema. The PDF generation was initially intended to be one of the export methods of the TEI data, located at the very end of the product development. As soon as it was implemented, we realized that this type of data visualization can be used to expose semantic and structural discrepancies in the source data. We therefore moved PDF export up the TEI text workflow.
This implementation of PDF print bears similarity to the so-called Agile development method. In Agile the software product is built in small progressive chunks, and each of the development cycles includes feature clarification, design, coding, and testing. It is conducted by cross-functional teams of people who house a range of expertise including programming, testing, analysis, database administration, user experience and infrastructure (Black 2017: 7).
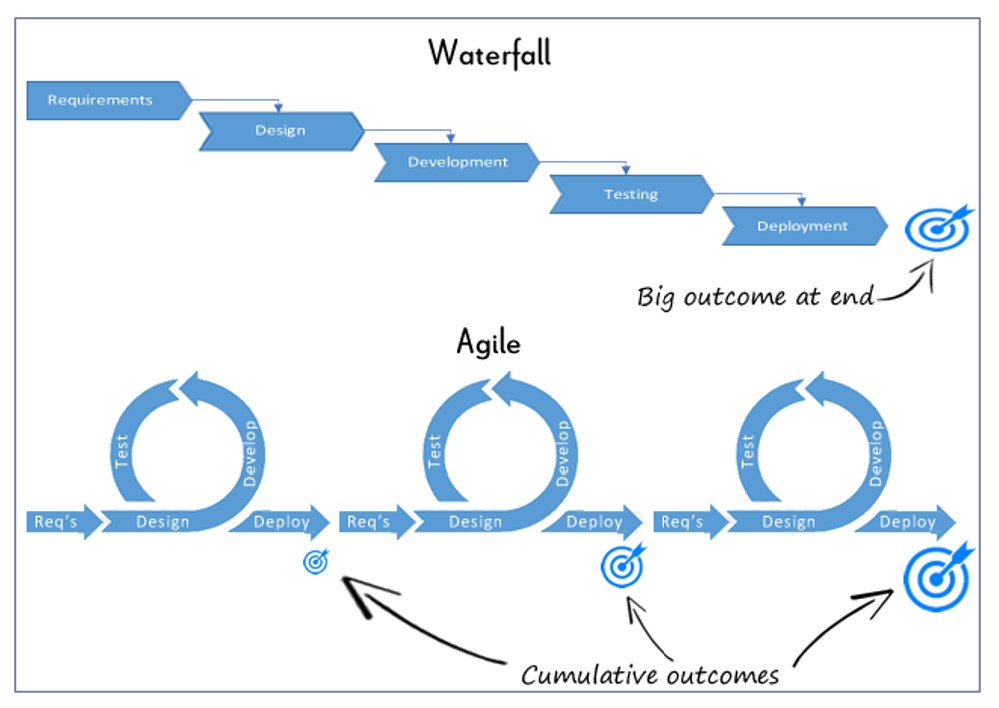
(Image source: http://crmsearch.com/images/agileandwaterfall.gif)
PDF creation at Salamanca abides by the principles of Agile software testing. It does not only start early in the data development and repeats with every subsequent step. It also breaks the traditional boundary between the software developers and researchers. In such QA4DH model researchers function as testers providing a direct feedback to the encoding team and thus actively participating in the development process. Researchers are used to dealing with a high degree of uncertainty, where not the software specification, but the deep knowledge of the subject and intuition are necessary to distinguish a “bug” from a “feature”. These two aspects — “fuzziness” of an error and a researcher skill set required from a tester — is what differentiates the conventional software quality assurance from quality assurance in digital humanities.
Bibliography
- Black, Rex, ed. 2017. Agile Testing Foundations: An ISTQB Foundation Level Agile Tester Guide. Swindon, UK: BCS, The Chartered Institute for IT.
- Crispin, Lisa. 2008. Agile Testing: A Practical Guide for Testers and Agile Teams. 1st ed. Upper Saddle River, NJ: Addison-Wesley Professional.
- Wenz, Viola, Arno Kesper, and Gabriele Taentzer. 2022. “Classification of Uncertainty in Descriptive Data Representing Scientific Knowledge,” March.
https://doi.org/10.5281/zenodo.6327011.