 Since its beginning in 2013, the Salamanca Project has been developing a text editing workflow based on methods and practices for sustainable and scalable text processing. Sustainability in text processing encompasses not only reusability of the tools and methods developed and applied, but also long-term documentation and traceability of the development of the text data. This documentation will provide an important starting point for future research work. Moreover, the text preparation must be scalable, since the Digital Source Collection comprises a relatively large mass of texts for a full-text digital edition project: in total, it will involve more than 108,000 printed pages from early modern prints in Latin and Spanish, which must be edited in an efficient and at the same time quality-assured manner.
Since its beginning in 2013, the Salamanca Project has been developing a text editing workflow based on methods and practices for sustainable and scalable text processing. Sustainability in text processing encompasses not only reusability of the tools and methods developed and applied, but also long-term documentation and traceability of the development of the text data. This documentation will provide an important starting point for future research work. Moreover, the text preparation must be scalable, since the Digital Source Collection comprises a relatively large mass of texts for a full-text digital edition project: in total, it will involve more than 108,000 printed pages from early modern prints in Latin and Spanish, which must be edited in an efficient and at the same time quality-assured manner.
In the following, I will introduce the sequence of stages that each work in the Digital Source Collection goes through, from locating a suitable digitization template in a public library to metadata and the completion of a full text in TEI All format, enriched with the project’s specifications.
One word about terminology: in the project’s daily communication, we use the term “work” to describe the entire intellectual entity an author and his publisher offer to the public under a unifying title. A work often consists of two or more volumes, which in physical form may or may not be bound as single entities. Each work has an internal structure composed of various elements as e.g., books (major parts), titles, chapters, questions, and paragraphs.
Inhaltsverzeichnis
Digitization
The print originals of the works we are interested in are held by libraries worldwide. Their digitization is usually carried out by the holding libraries or by service providers commissioned by them. The technical parameters of image digitization follow the specifications of the “DFG-Praxisregeln Digitalisierung” which gives information about resolution, color, data format, etc.
Once we acquire the facsimiles, they go through the following steps:
- First, we check them for completeness and any scanning errors such as turned corners and partially obscured type (quality control). Special features such as incorrect pagination/foliation, cross-outs with or without loss of text (censorship), loss of text due to damage to the paper (insect damage, watermarks, etc.) are noted in a protocol, as is the exact sequence of pagination/foliation and, if applicable, unpaginated pages.
- Then, we number facsimiles according to an internal identification number following the structure:
[work ID]-[volume indicator]-[facsimile number]
For example, the first scan of Work 1, Volume 1 (Avendaño, Thesaurus Indicus, vol. 1) would be numbered as:
W0001-A-0001 - We upload facsimiles on the server to simplify the location of any specific page and to give the whole team access to the scans at any time.
- Afterwards, bibliographic metadata of the original print is collected in detail with the assistance of the librarians at the Max Planck Institute for Legal History and Legal Theory (Frankfurt a.M.) and we set it in a teiHeader-element within an XML-file. This information complies with the international RDA standards (Resource Description and Access), the internationally authoritative standard for the indexing of publications. For more details, visit 5.1. Bibliographic Description, of our Edition Guidelines.
- Finally, we publish the facsimiles (formatted as jpg files with reduced data volume) with their bibliographic metadata on the project’s website under open access conditions. This ensures that users of the Digital Collection are enabled to access and consult the facsimiles as quickly as possible, a step taken in consideration of the length of the process to create a publishable full text edition.
See the project’s overview of published works, using the filter “facsimiles”.
Transcription Instructions for External Encoders
In this stage, we create a document with transcription instructions. It contains the facsimiles’ location, possible missing pagination, or other printing issues, as well as instructions about how to handle specific text phenomena (the structure and/or layout of the text). This information is also complemented by the general instructions employed for dealing with character encoding, structural phenomena (e.g. marginalia) or typographical peculiarities (font types, decorative initials, etc.). Our external service providers receive general and specific transcription instructions (in German) to encode the full text.

Capturing text in TEI Tite
Two external service providers, Textloop (Norderstedt) and Grepect (Garbsen) are in charge of the full text transcription. They work with a combination of OCR and manual post-processing (Textloop) or in a double keying process (Grepect.). Our transcribed texts are delivered first in TEI-Tite XML format with basic annotations of specific text phenomena and typographic features. TEI-Tite was developed by the TEI specifically for transcriptions by external encoders. Compared to the generic TEI All-Schema, it has a reduced, compact vocabulary and is therefore particularly well suited for producing easy-to-understand encoding instructions while also allowing manual transcription and annotation directly in the XML through a low tag overhead.
After the completion of the transcription by the external encoders, we check their text annotations and, if necessary, we supplement or correct them.
Pipeline Start
The text preparation (the transformation, editing, and correction of the full texts delivered by the service providers) consists of many individual steps, some of which are performed automatically, others manually or semi-automatically. There are dependencies between the individual steps regarding the execution sequence. The resulting complexity poses several practical challenges for text preparation, for example the coordination of several workstations working on a text or to collision-free versioning of the different processing stages of a text. To meet these challenges and to achieve the highest possible efficiency, reproducibility, and documentation of the text preparation, we use the concept of so-called pipe lining.
The basic idea of pipe lining is that all transformations of a data set – whether automatic XSLT transformations or manual editing steps – can be defined as programs that can then be called sequentially as subroutines from a higher-level program (the pipeline), whereby the output of one step (e.g., manual structural annotation) is the input of the next step (e.g., automatic addition of @type attributes in <div>). The automatic executability of XSLT programs is, so to speak, obvious; however, the manual editing steps can also be defined subsequently as fully automatically executable routines, namely by a before-after comparison of the modified file. In this way, all steps of text editing can be combined in a predefined sequence in a pipeline program that can be executed at the push of a button and can restore all editing stages of a text at any time. This not only considerably simplifies the systematic processing of the individual work steps, but also leads to comprehensive documentation (in the form of program code) and thus sustainability in text preparation.
We chose the open-source software build tool ANT, which prescribes the configuration of pipelines in an easily readable XML format, whereby the pipelines are ultimately coded in the same data format as the texts to be prepared. ANT allows the definition of subroutines of any size, so that manual and automatic transformations can be encapsulated at will and formed into modules or code snippets that can be used across texts.
Here is a short example of our pipeline in a build.xml file, which shows structural annotation and TEI-Transformation, one manual and one automatic step respectively.
<?xml version="1.0" encoding="UTF-8"?>
<project basedir="." name="W0030" default="finalize">
<property name="diff.dir" value="diff"/>
<property name="log.dir" value="log"/>
<property name="xml.dir" value="xml"/>
<property name="xsl.dir" value="xsl"/>
<property name="xslt.log" value="${log.dir}/${ant.project.name}_xslt.log"/>
<property name="xslt.processor" value="../../../lib/xsltproc/Saxon-HE-9.8.0-12.jar"/>
<property name="xslt.class" value="net.sf.saxon.TransformerFactoryImpl"/>
<property name="orig.file" value="../../orig/grepect/W0030/adw_mainz_Die Schule von Salamanca_W0030.xml"/>
<target name="initialize">
<echo>Initializing W0030.</echo>
<mkdir dir="${xml.dir}"/>
<mkdir dir="${log.dir}"/>
<copy file="${orig.file}" tofile="${xml.dir}/W0030_000.xml"/>
<xmlvalidate file="${xml.dir}/W0030_000.xml" lenient="true"/>
</target>
<!--Original transcription copy-->
<target name="cp-000" depends="initialize">
<copy file="${xml.dir}/W0030_000.xml" tofile="${xml.dir}/W0030_v1-0.xml"/>
<echo>Checkpoint: W0030_v1-0.xml (W0030_000.xml).</echo>
<delete file="${xml.dir}/W0030_000.xml"/>
</target>
<!--Manual structural annotation-->
<target name="patch-000"> <!-- depends="cp-000" -->
<echo>Structural annotation.</echo>
<patch originalfile="${xml.dir}/W0030_v1-0.xml" destfile="${xml.dir}/W0030_001.xml" patchfile="${diff.dir}/W0030_000.diff"/>
<delete file="${xml.dir}/W0030_000.xml"/>
</target>
<!--Automatic Transformation-->
<target name="xslt-001"> <!--depends="patch-000"-->
<echo>Transformation TEI tite to TEI-All.</echo>
<record name="${xslt.log}" action="start" loglevel="verbose"/>
<xslt force="true" in="${xml.dir}/W0030_001.xml" out="${xml.dir}/W0030_002.xml" style="${xsl.dir}/W0030_001.xsl" classpath="${xslt.processor}">
<factory name="${xslt.class}"/>
</xslt>
<record name="${xslt.log}" action="stop"/>
</target>
<target name="finalize" depends="xslt-001">
<echo>Reached end of pipeline.</echo>
</target>
</project>The following are the most important steps of the pipeline.
Structural Annotation
Working still in TEI-Tite format, we annotate structural text units (librum, pars, caput, quaestio, etc.), cross-references, and language information, and resolve unclear marks as far as possible. This largely manual work is most easily accomplished in the TEI-Tite format since this reduced format is relatively clear and the encoded text itself is easily readable. At the same time, TEI-Tite is compatible for an automatic transformation to TEI All.

Project-Specific TEI Transformation
To process the full texts further in editor, database and web application, we have to transform the data into the project specific TEI format. For this transformation, we have developed a self-tailored XSLT program, by means of which the TEI Tite-XML of the transcribed „raw versions“ of the texts is automatically transformed into the „Salamanca“ TEI-All format. This resulting TEI document has both, the metadata (compiled at the beginning of the workflow) in a <teiHeader> element and all elements and attributes adapted to TEI-All.
![]()
Automatic Corrections and Enrichment
Once texts are transformed in TEI-All, we transform them with further self-tailored, and adaptable XSLT-programs, which are located intern in our SVN-Repository and used in our pipeline. In this process there are dependencies among versions, therefore most of our programs follow a specific sequence. These resources are now available for the following purposes:
Hyphenated words annotation
Annotation of hyphenated or unmarked word separations at the line break.

| In an early TEI-All-version | After XSLT-Transformation |
DE POENI<lb type="nb"/>TENTIA Or…DE POENI-<lb/>TENTIA |
DE POENI<lb rendition="#hyphen" break="no" xml:id="W0030-00-0001-lb-0003"/>TENTIA |
Special characters annotation
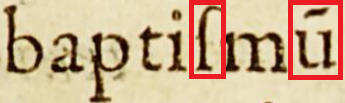
Identification and annotation of special characters (e.g., brevigraphs) for automatic and manual resolution of abbreviations.
| In an early TEI-All-version | After special character XSLT-Transformation |
baptiſmũ |
|
For further information visit our edition guidelines, 3.2.2. Non-Standard Characters and our special characters xml document.
Abbreviation recognition and resolution
Automatic recognition and resolution of abbreviations using the previous step of special character annotation and our abbreviation lists. This abbreviation tagging XSLT-Transformation expands words, which in 100% of the cases are expanded the same way. For instance, autẽ always expands as autem.

| Before transformation | After Abbreviations‘ XSLT-Transformation |
aut<g ref="#chare0303">ẽ</g> |
Abbreviation: autẽ Expansion: autem<choice><abbr>aut<g ref="#chare0303">ẽ</g></abbr><expan resp="#auto">autem</expan> |
xml:id(s) Tagging
Line and column numbering; also, unique marking of relevant structural units (e.g. chapters, paragraphs, citation anchors, page/column/line breaks, etc.) by means of so-called xml:id attributes. These xml:id(s) are constructed based on the following structure, e.g.: First line (<lb/>) of Work 30, facsimile 2:
<lb xml:id="W0030-00-0002-lb-0001"/>| work ID | volume number | facsimile number | element code | numbering |
| W0030 | 00 (monography) | 0002 | lb | 0001 |
As soon as we transform the text in TEI-All format, and after every automatic correction, it is continuously validated with the following tools: first with the project’s schema, which follows the TEI standard. Second with a schematron designed to find elements, attributes, and text that, although valid and well-formed, might not follow the specifications of our edition guidelines.
Manual Corrections
After automatic processing, texts are first transferred to a process of manual scholarly correction and editing. The core of this specialist manual editing work consists of resolving remaining unclear marks from encoders, correcting erroneous transcriptions and original printing errors, and above all resolving brevigraphs and correcting word separations. The aim is to eliminate transcription and typographical errors as completely as possible; regarding the resolving of brevigraphs, we needed to find a balance between keeping the text form as close as possible to the original on the one hand and making it easier to read on the other.
This correction is largely done manually in the edition software oXygen. This editor has an XML text view, which is used for structural annotation, and an author view, which our project team adapted in a plug-in that provides our expert editors with tools to facilitate proofreading, as well as some features to the project-specific requirements.
Once these manual modifications are done, we check and correct them using list-based, semi-automatic correction xQuery stylesheets developed by our project team. As a result, the programs find probable errors, and save them into lists for checking word forms, unresolved abbreviations, or incorrect word separations in the texts. These correction programs compare word forms of the TEI-encoded text with the word forms deposited in dictionaries for Latin and Spanish, as well as with unique word forms occurring in the text itself.
The lists produced by this automatic checking are then given back to the scholarly editors of the texts; they go through the lists manually, correcting the remaining mistakes.
Post-Corrections
After the work on the correction lists, the text is ready for the final step of semi-automatic corrections and validation: at this stage, elements and attributes should be valid and well-formed according to the project’s schema, the schematron and the standards TEI All.
Then, we control hyphenation and abbreviation structures. For instance, tag overlap inside <choice> elements. The abbreviation and its respective expansion should contain the same hyphenation information. The abbreviation “auersandũ” should be expanded as “auersandum”, and both should also contain : <lb/> and its attributes as follows:
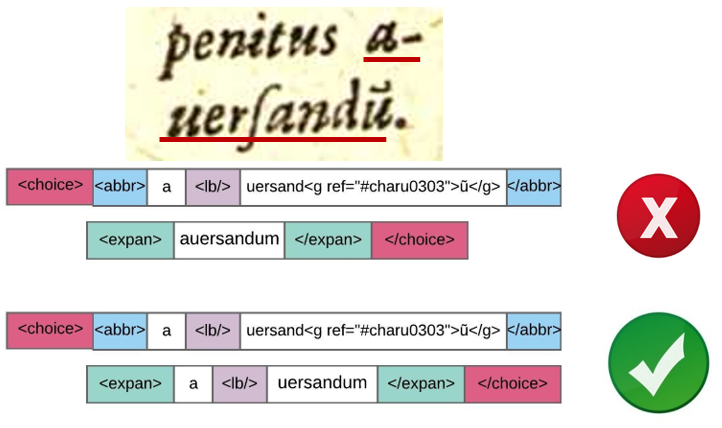
We also tag the xml:ids and special characters mentioned in “Automatic Corrections and Enrichment” again. This help us to ensure that all elements and lines in the text can be easily located, as well as all characters are properly tagged, just in the case some words lack them due to manual corrections or expansions.
In this last phase, we check the metadata against the respective entries in the catalog of the Max Planck Institute for Legal History and Legal Theory; we also confirm the date of publication, the list of changes to the text and ensure that all the editors who worked on this text are named.
Finally, if the text has no further errors after validation with the schema and schematron, it is ready for the online publication in the project’s Digital Collection of Sources.