
Polina Solonets and Maxim Kupreyev, members of the project team, participated in the poster presentation as a part of the DARIAH Annual Event 2023 taking place on June 6th to June 9th in Budapest. This year the conference topic was ‘Cultural Heritage Data as Humanities Research Data?’. Polina and Maxim introduced their approach to sustainable workflow organisation when working on a large scale edition and presented a poster entitled: ‘Sustainable Practices for the Large-Scale TEI Editions at the School of Salamanca Text Collection’.
Etiqueta: Digital Humanities
(English) Word frequencies in the Digital Collection of Sources in the Works of the School of Salamanca.

The fundamental importance of the School of Salamanca for the early modern discourse about law, politics, religion, and ethics is widespread among of philosophers and legal historians. These early modern texts extend beyond the core authors, and serve to analyze the history of the Salamanca School’s origins and influence, as well as its internal discourse contexts within the context of the future dictionary entries.
Especially on the topic of dictionaries, the idea to test and explore our corpus with modern NLP applications came up in the project a long time ago. We often asked ourselves which lemmas or information we could find with help of a text analysis, and above all how complex this realization would be with our data. Thus, in 2021 we started a natural language processing task (word frequency distribution) by using the Python programming language to explore our corpus and establish groundwork for further text mining. Continuar leyendo «(English) Word frequencies in the Digital Collection of Sources in the Works of the School of Salamanca.»
(English) The School of Salamanca Text Workflow: From the early modern print to TEI-All.
 Since its beginning in 2013, the Salamanca Project has been developing a text editing workflow based on methods and practices for sustainable and scalable text processing. Sustainability in text processing encompasses not only reusability of the tools and methods developed and applied, but also long-term documentation and traceability of the development of the text data. This documentation will provide an important starting point for future research work. Moreover, the text preparation must be scalable, since the Digital Source Collection comprises a relatively large mass of texts for a full-text digital edition project: in total, it will involve more than 108,000 printed pages from early modern prints in Latin and Spanish, which must be edited in an efficient and at the same time quality-assured manner.
Since its beginning in 2013, the Salamanca Project has been developing a text editing workflow based on methods and practices for sustainable and scalable text processing. Sustainability in text processing encompasses not only reusability of the tools and methods developed and applied, but also long-term documentation and traceability of the development of the text data. This documentation will provide an important starting point for future research work. Moreover, the text preparation must be scalable, since the Digital Source Collection comprises a relatively large mass of texts for a full-text digital edition project: in total, it will involve more than 108,000 printed pages from early modern prints in Latin and Spanish, which must be edited in an efficient and at the same time quality-assured manner.
In the following, I will introduce the sequence of stages that each work in the Digital Source Collection goes through, from locating a suitable digitization template in a public library to metadata and the completion of a full text in TEI All format, enriched with the project’s specifications. Continuar leyendo «(English) The School of Salamanca Text Workflow: From the early modern print to TEI-All.»
Enfoques digitales de la historia en la Temprana Edad Moderna: marcos, herramientas y recursos (Taller)
Las fuentes textuales de la Temprana Edad Moderna plantean desafíos específicos con respecto a su adquisición, análisis y representación digital. En primer lugar, la digitalización de fuentes de textos completos es compleja, requiere mucho tiempo y está lejos de ser un proceso completamente automatizable, al menos de modo que pueda alcanzar a satisfacer las necesidades de los investigadores académicos. En segundo lugar, el análisis digital de datos se basa en modelos de datos históricos y textuales específicos y en ontologías que deben llevarse a cabo mediante el estudio académico y la anotación manual de los textos, lo cual requiere mucho tiempo. Por otro lado, las aplicaciones automáticas enfrentan una importante escasez de 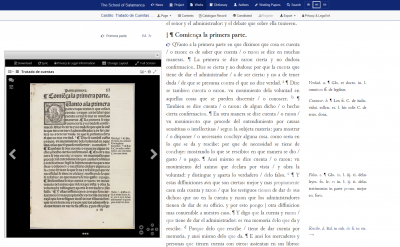 herramientas de procesamiento de lenguaje natural aplicables a idiomas de «bajos recursos» como el español o el latín de la Primera Modernidad, careciendo también de recursos lingüísticos y semánticos apropiados para estos períodos e idiomas específicos. Finalmente, aunque las discusiones sobre representaciones de datos (textuales) y visualizaciones se encuentran en el centro de los esfuerzos actuales de las humanidades digitales, todavía no existe un consenso mínimo acerca de cuáles sean las mejores prácticas para representar los textos e informaciones específicas de la Modernidad Temprana en su compleja variedad (multimedial / multimodal). Estas dudas se extienden tanto a las formas digitales a emplear, como a sus versiones, formas de participación lectora, arquitecturas de programas subyacentes, etc.
herramientas de procesamiento de lenguaje natural aplicables a idiomas de «bajos recursos» como el español o el latín de la Primera Modernidad, careciendo también de recursos lingüísticos y semánticos apropiados para estos períodos e idiomas específicos. Finalmente, aunque las discusiones sobre representaciones de datos (textuales) y visualizaciones se encuentran en el centro de los esfuerzos actuales de las humanidades digitales, todavía no existe un consenso mínimo acerca de cuáles sean las mejores prácticas para representar los textos e informaciones específicas de la Modernidad Temprana en su compleja variedad (multimedial / multimodal). Estas dudas se extienden tanto a las formas digitales a emplear, como a sus versiones, formas de participación lectora, arquitecturas de programas subyacentes, etc.
Algunos de los métodos e infraestructuras desarrollados para responder a estos desafíos son bien conocidos. Por ejemplo, la adquisición de datos (textos) históricos puede mejorarse a través de formas de colaboración abierta distribuida (crowdsourcing) y edición digital colaborativa y técnicamente facilitada por herramientas de anotación colaborativas; los modelos de datos abiertos vinculados y las infraestructuras relacionadas pretenden, a su vez, proporcionar medios para anotar los datos de modo que se ajusten a los estándares interoperables de la web semántica. Asimismo, hay una cantidad cada vez mayor de recursos lingüísticos y geográficos específicos, así como de herramientas adaptadas por y para proyectos individuales de investigación sobre la Modernidad. Estos proyectos podrían beneficiarse potencialmente a través de la comunicación y el intercambio de recursos y herramientas. Con el fin de fortalecer el uso comunitario de marcos y herramientas ya existentes, y de compartir métodos y herramientas que hasta ahora eran desconocidos -con excepción de algunos casos puntuales-, parece crucial proponer un intercambio de conocimientos teóricos, metodológicos y prácticos acerca de los planteamientos digitales que barajan los proyectos de investigación sobre la Primera Modernidad.
Con la intención de fomentar este intercambio interdisciplinario a nivel intercultural, el Instituto Max Planck para la Historia del Derecho Europeo y el proyecto «La Escuela de Salamanca: una colección digital de fuentes y un diccionario de su lenguaje jurídico-político» organizan un taller con expertos en humanidades digitales de América Latina y Europa en el Instituto Max Planck de Argentina – Instituto de Investigación en Biomedicina de Buenos Aires.
El taller incluirá un pequeño número de presentaciones de proyectos individuales y ofrecerá, además, la oportunidad para la discusión conjunta en sesiones dedicadas al trabajo conjunto con herramientas técnicas, métodos y marcos, así como con recursos (lingüísticos, geográficos, ontológicos, etc.) para el estudio de fuentes y contextos modernos tempranos.
Fecha: 23 de Octubre 2018
Lugar: Instituto Max Planck Argentina – Instituto de Investigación en Biomedicina de Buenos Aires, C1425FQD, Godoy Cruz 2390, Buenos Aires
La lengua del taller será el español, aunque contribuciones en inglés también serán posibles.
Para inscribirse como participante en el seminario, contáctenos, por favor, hasta el 15 de octubre de 2018 en: salamanca@rg.mpg.de.
Programa
14:00 Thomas Duve: Bienvenida
14:05 Andreas Wagner / David Glück: Introducción
14:15 Andreas Wagner: Investigación en humanidades digitales relacionada con Iberoamérica en el Instituto Max Planck para la Historia del Derecho Europeo.
14:45 David Glück: Métodos, marcos y recursos lingüísticos en la edición digital de «La Escuela de Salamanca»
15:15 Debate.
15:30 Sesión práctica: Marcos, métodos y herramientas digitales para la historia de la Temprana Edad Moderna.
16:30-17:00 Pausa.
17:00 Gimena del Rio Riande, Romina De León, Nidia Hernández (HD CAICYT Lab, CONICET): Integrando la anotación, herramientas de edición digital y recursos GIS: Experiencias prácticas del proyecto LatAm (presentación del proyecto y sesión práctica).
18:00 Debate.
18:30 Cierre del taller y despedida.
(Alemán) iiif in der Schule von Salamanca
Das iiif Consortium und die weitere iiif Community haben Standard-Protokolle definiert, wie man sie in der Darstellung von Bildressourcen benötigt. Die Protokolle sind als Beschreibungen von «Schnittstellen» formuliert, d.h. es wird beschrieben, unter welcher Adresse, mit Hilfe welcher Parameter der Dienst eine bestimmte Funktion anbieten soll. In dieser Weise gibt es Beschreibungen von Zoom-/Rotations-/Ausschnitts-/Format-Konversions- und ähnlichen Diensten in der iiif image API, die aktuell in Version 2.1.1 vorliegt. Ferner Beschreibungen von Zugangsmanagement- und Authentifikationsservices sowie von Such-Funktionen in der Authentication API bzw. der Search API, beide jüngeren Datums und erst in der Version 1.0 vorliegend. Beschreibungen von Video- und Audio-Daten (z.B. für die in diesem Fall hinzukommenden Zeit-Indices der Ressourcen) sind in Vorbereitung.
Continuar leyendo «(Alemán) iiif in der Schule von Salamanca»
(English) Code Release and Open-Source Development of the ‘School of Salamanca’ Web Application
On 1 March 2018, we have released the code of the web application of the ‘School of Salamanca’ project’s digital edition (https://salamanca.school) as free and open source software (under the MIT license) on GitHub: https://github.com/digicademy/svsal, where the development process and the versioning of our web application takes place exclusively from this date onward. The publication of our web application’s code represents the first major code release of the project; other parts of our digital infrastructure and the research data will be published separately.
The web application, now having reached version 1.0, has been developed since 2014 and, more precisely, consists of an eXist-db application package. While this package can be downloaded and deployed in any eXist-db (version 3.6+) instance, it must be mentioned that, in order to function correctly, the web application draws upon the integration with further, external services: for example, an iiif-conformant image server (image and presentation APIs) allowing for the incorporation of facsimile images in the reading views of our works, or a SphinxSearch server providing lemmatized and cross-language search results for the texts. Notwithstanding these current caveats in portability of the application package, and although there still remains much to be achieved with regards to the functionality of our web application, the code underlying central features of the application (such as the endless-scrolling segmentation of texts in the reading view, the content negotiation-based URI-linking of texts and text segments, and others) is fully available now and can be utilized or serve as an example for similar projects, for instance. For a more extensive and detailed description of current features, caveats, and provisos of the application please refer to: https://github.com/digicademy/svsal.
The software is tagged with a DOI so that it can be cited: https://doi.org/10.5281/zenodo.1186521
(Inglés) What’s in a URI? Part I: The School of Salamanca, the Semantic Web and Scholarly Referencing

Starting from experiences of the the philosophical and legal-historical project «The School of Salamanca. A digital collection of sources and a dictionary of its juridical-political language», this article discusses an experimental approach to the Semantic Web.1 It lists both affirmative reasons and skeptical doubts related to this field in general and to its relevance for the project in particular. While for us the general question has not been settled yet, we have decided early on to discuss it in terms of a concrete implementation, and hence the article will also describe preliminary goals and their implementation along with practical and technical issues that we have had to deal with.
In the process, we have encountered a few difficult questions that — as far as we could determine — involve (arguably) systematic tensions between key technologies and traditional scholarly customs. The most important one concerns referencing and citation. In the following, I will describe a referencing scheme that we have implemented. It attempts to combine a canonical citation scheme, some technologies known primarily from semantic web contexts and a permalink system. Besides the details of our particular technical approach and the very abstract considerations about risks and benefits of the semantic web, I will point out some considerable advantages of our approach that are worthwhile pursuing independently of a full-blown semantic web offering.
(Deutsch) CfP: Forum RG RECHTSGESCHICHTE – LEGAL HISTORY 24 (2016)

Wir laden sehr herzlich ein zur Einreichung von Beiträgen zu einem Diskussionsforum der Zeitschrift RG RECHTSGESCHICHTE – LEGAL HISTORY mit dem Titel «Die geisteswissenschaftliche Perspektive: Welche Forschungsergebnisse lassen Digital Humanities erwarten?/With the Eyes of a Humanities Scholar: What Results Can We Expect from Digital Humanities?» Dieses Diskussionsforum wird durch das Projekt für die Zeitschrift RG RECHTSGESCHICHTE – LEGAL HISTORY organisiert.
Die Beiträge sollen dezidiert die geisteswissenschaftliche Perspektive einnehmen und die bereits gemachten Erfahrungen in der forschungspraktischen Arbeit mit dem Instrumentarium der DH thematisieren. Im Mittelpunkt steht die Interaktion zwischen geisteswissenschaftlichen Erkenntnisinteressen und digitalen Tools: Wie verändern digitale Möglichkeiten Forschungsinteresse und Methode? Continuar leyendo «(Deutsch) CfP: Forum RG RECHTSGESCHICHTE – LEGAL HISTORY 24 (2016)»